DAC/ADCとDSPの統合ICにより、広帯域マルチチャンネル・システムの性能を改善する
はじめに
ワイヤレス・システムでは、数十年にわたってチャンネル数の増加と帯域幅の拡大が進められています。最新の通信システムや、レーダー・システム、計測システムの進化を後押しするのは、データ・レートとシステム全体の性能に対する要件です。それらにより、パワー・エンベロープとシステムの複雑さが増し、電力密度とコンポーネント・レベルの機能の重要性が高まります。
上述した状況に対応するために、半導体メーカーは、ICに集積するチャンネルの数を増やし、チャンネルあたりの消費電力の削減を図ってきました。また、より複雑な機能をデジタル・フロント・エンドに集積することで、オフチップのハードウェアの設計を簡素化できるようにしました。従来、その種のハードウェアとしては、ASICやFPGAが使用されていました。それらによって実現される機能は、フィルタ、ダウンコンバータ、NCO(Numerically Controlled Oscillator:数値制御発振器)などの一般的なものから、アプリケーション固有のより複雑な処理に至るまで多岐にわたります。
チャンネル数が多いシステムを開発する場合、シグナル・コンディショニングとキャリブレーションに関して、より複雑な問題に直面することになります。上記のアーキテクチャでは、チャンネルごとに、独自のフィルタや他のDSP(デジタル信号処理)ブロックが必要になるケースが多いからです。消費電力の削減を実現するためには、そのような設計から、ハード化(hardened)したDSPを採用した設計への移行を進める必要があります。ここでいうハード化とは、FPGAを使用してソフトウェア(HDLコード)ベースでDSP機能を実現するのではなく、専用ハードウェアとして実装するということです。
本稿では、上記の内容に関連して行った実験の結果を紹介します。その実験では、各16個の送信/受信チャンネルを備えるサブアレイを使用しました。また、デジタイザICが備えるハード化されたDSPブロック(以下、ハード化DSP)を使用して、全送受信チャンネルのキャリブレーションを実現します。それにより、このマルチチャンネルのシステムは、FPGAベースのDSPブロックを使用する場合と比べて、サイズ、重量、消費電力の面で高い性能が得られることがわかりました。更に、このシステムにおけるFPGAのリソースの使用率を調べることで、ハード化DSPによってマルチチャンネル・プラットフォームの設計上の重要な課題を解決できることも明らかになりました。
DSPブロックの役割
現実の世界の信号を合成(送信用の信号の生成)したり、受信したりする場合には、アプリケーションに求められる性能を実現するために、何らかの解析や処理を行う必要があります。例えば、シグナル・チェーンで生じる振幅のドループや平坦性の問題を解消するためには、補償用のフィルタが使用されます。図1に示したのは、ゲインと平坦性を補償するためのフィルタ(図中のpFIR)の例です。このフィルタは、所定の周波数帯域にわたって不完全性を補正できるように設計されています。これを使うことで、下流の回路にとって、より理想的な応答を生成することが可能になります。

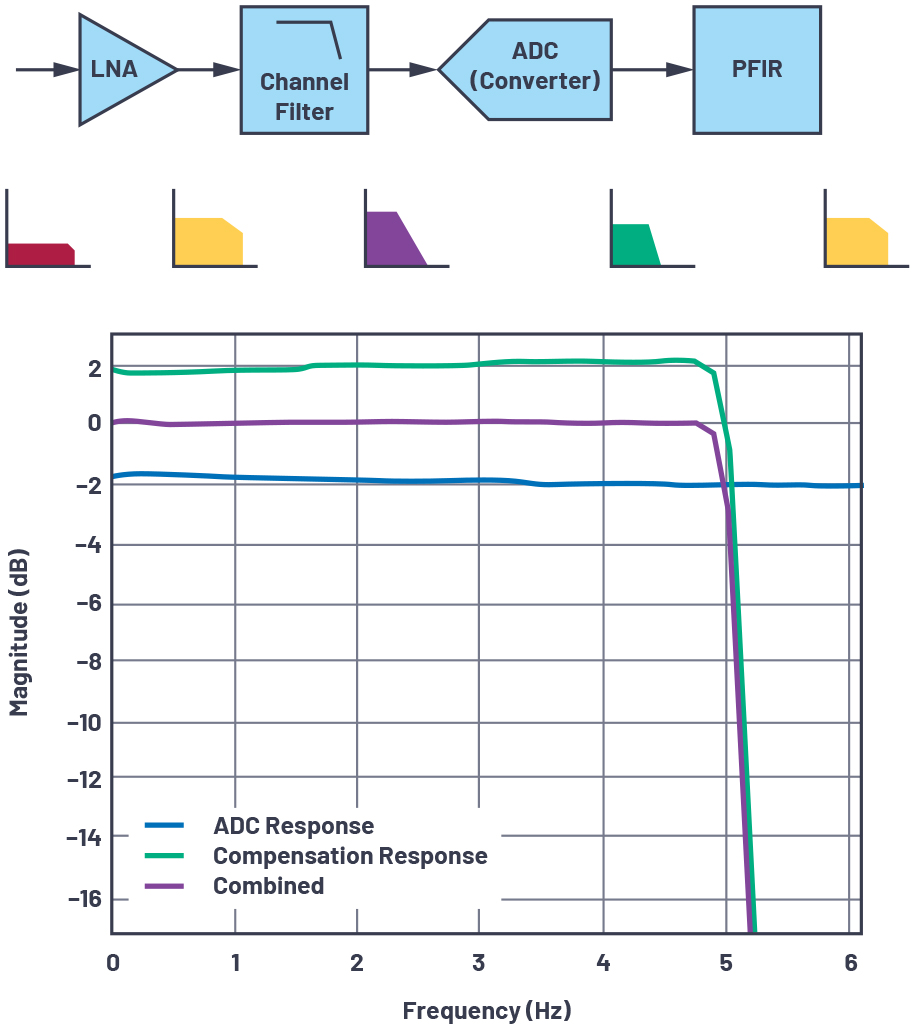
図1. ADCの振幅応答の補償。デジタル・フィルタ(pFIR)を使用することにより、帯域内で平坦な応答が得られるよう改善を図ることができます。
マルチチャンネルのシステムでは、上記の処理をチャンネルごとに独立に制御できるようにする必要があります。つまり、他のチャンネルからは分離された状態で、各チャンネルの性能を調整できるようにしなければなりません。そのため、システムでは個別のDSPブロックを使用し、チャンネルの振幅/位相のアライメントを実施すると共に、通過帯域内におけるゲインの平坦化を行います。各チャンネルもシステムも、それぞれ固有のものなので、構成、環境、ハードウェアのロットに応じ、DSPによって個別に調整を行う必要があります。
DUP/DDCのブロック
本稿では、モノリシックのD/Aコンバータ(DAC)とA/Dコンバータ(ADC)に集積されるDSPブロックを取り上げます。それらのハード化DSPを使えば、デジタル・アップ・コンバータ(DUC)とデジタル・ダウン・コンバータ(DDC)の機能を実現できます。ADC/DACのデータ・パスでは、図2のようなDUC/DDCがよく使用されます。これらは、以下に示すような機能を実現するために使用されます。
- コンバータ(ADC/DAC)のサンプリング・レートをデジタル・インターフェースのデータ・レートと合致させるために、インターポレーション(DUC)、デシメーション(DDC)を実施します。
- DAC の入力用に合成したデータ(DUC)と ADC から出力されるデジタル化されたデータ(DDC)の周波数を変換します。
- ベースバンド・プロセッサ(BBP)へのインターフェース上で、送信するデジタル・データをチャネライズすることができます。
- 各チャンネルのゲインをデジタルで制御することが可能になります。そうすれば、生成するコードの値をシステムのフルスケールの値に近づけることができます。
- デジタル・データ・リンクを使うことなく、単純なトーン用のデジタル・データを入力するだけで、システムを容易に立ち上げられます。
- 各チャンネルの位相を、共通のリファレンスを基準としてアライメントすることが可能になります。
コンバータに対してオフロードするデータ、またはコンバータからオフロードされるデータのレートを、サンプリング・レートとは異なる値に設定したいケースは少なくありません。それによって、システムの消費電力を削減したり、システム全体の柔軟性を高めたりすることが可能になるからです。DUC/DDCは、この目的を果たすために使用されます。DUCを使用できる場合、DACのサンプリング・レートより低いレートでBBPからデータ(波形データ)を送信することができます。図2(上)に示したインターポレーション用のサブブロックをご覧ください。これにより、波形データに対するインターポレーションを実施します。その結果、DACでは、BBPからの送信時よりも高いレートで信号を合成できます。続いて、図2(下)に示したデシメーション用のサブブロックをご覧ください。この例の場合、ADCでは受信した信号を高いサンプリング・レートでデジタル化します。DDCブロックによってそのデータにデシメーションを適用することで、より低いレートでデータをBBPに送信することが可能になります。

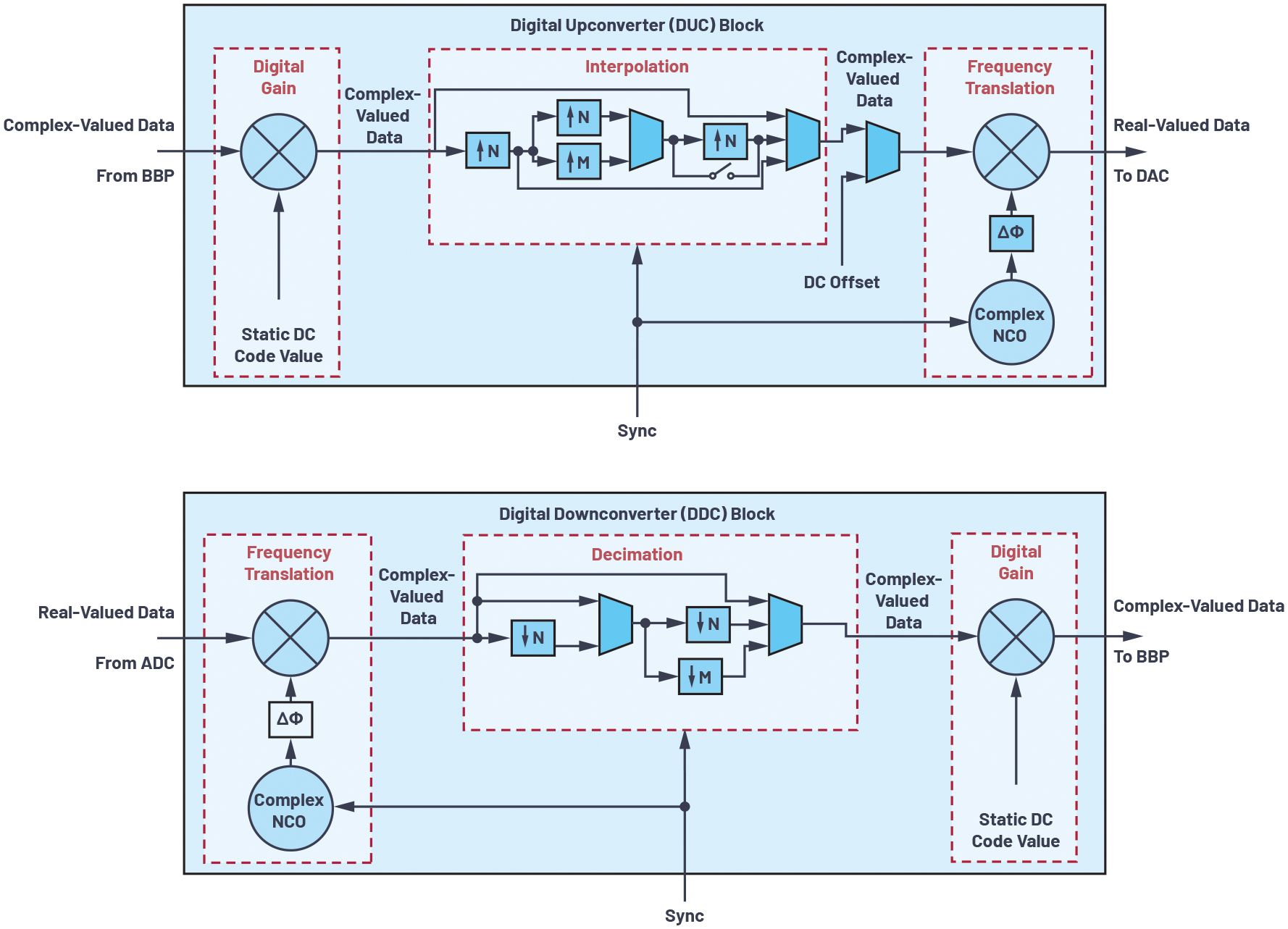
図2. DUCとDDCの回路ブロック。コンバータIC上で多くの有用なDSP機能を提供します。
また、デジタル・インターフェースを介してBBPとの間でやり取りする信号よりも高い周波数のアナログ信号を合成/解析(受信)したいケースがあります。その場合には、デジタル領域における周波数変換が必要になります。図2に示したように、多くのシステムでは、この周波数変換を実現するためにDUC/DDC内の複素NCOを利用します。NCOは、局部発振器(LO)に相当する信号を生成するデジタル信号発生器だと見なすことができます。NCOが生成した信号は、同じくDUC/DDC内にあるデジタル・ミキサーに送信されます。その結果、DACに送信される信号の周波数を高めたり(DUC)、ADCから送出される信号の周波数を下げたりする(DDC)ことが可能になります。多くの場合、デジタル領域での周波数変換を行うと、デジタル・ミキサーからの出力はI/Q(同相/直交位相)データのような複素数データとなります。そして、それらのデータは単一のデジタル・チャンネルに沿って伝搬し、最終的にはADCによってサンプリングされた実数値に相当するデータとなります。同様に、DUCのデジタル・ゲイン・ブロックに存在するデジタル・ミキサーには複素数データが入力されます。デジタル・ミキサーの出力は、DACに入力される前に実数データとなります。
また、DUC/DDCを使えば、コンバータの瞬時帯域幅に対応する複数のデジタル・チャンネルを実現することができます。その結果、BBPによって、サブアレイが備えるコンバータの数よりも多くのデータ・ストリームを合成/解析することが可能になります。2個の狭チャンネルを分離する必要がある場合には、信号の合成/解析を改善可能なシステムを実現することができます。
図2のように、DUC/DDCには、デジタル・ゲイン・ブロックが設けられていることが少なくありません。このブロックは、サブブロック内にあるデジタル・ミキサーにスタティックなDC値(デジタル・コード)を与えることで機能します。これを使えば、フルスケールの値に近いコードを得ることができます。なお、フルスケールの値は、デジタル・インターフェースで扱うビット数によって決まります。同様に、デジタル・ミキサーにスタティックなDC値を連続的に与えれば、ベースバンドのデータの代わりにDCオフセットの連続波(CW)トーンを得ることが可能です。BBPとの間にJESD204B/JESD204Cに対応するデータ・リンクを確立することなく、DACによってアナログのCWトーンを簡単に合成することができます。
図2に示すように、多くの場合、NCOの出力部には位相オフセットのブロックが設けられます。システムには、共通のベースラインとなるリファレンスが存在します。それを基準として、チャンネル間に生じている位相の問題を補正するために、位相オフセットを使用することができます。各DUC/DDCが備えるNCOが出力する信号の位相を定められた量だけずらせば、各チャンネルの位相のアライメントを実現することができます。各チップの同期をとるためのアルゴリズムと併用すれば、すべてのチャンネル間に、NCOの位相オフセットによって修正可能なデタミニスティックな位相関係を持たせられます1。図3に、1つの実験結果を示しました。これは、16チャンネルのI/Qデータを同時に受信した結果です。実験においては、各受信データ・パスのNCOに位相オフセットの値を設定しました。それにより、厳密な位相アライメントが実現されています。図3(左)はアライメント実施前の波形、同(右)はアライメント実施後の波形を表しています。なお、このデジタル補正により、各チャンネルのフロント・エンド回路に存在するRF/マイクロ波の問題も補正することが可能です。

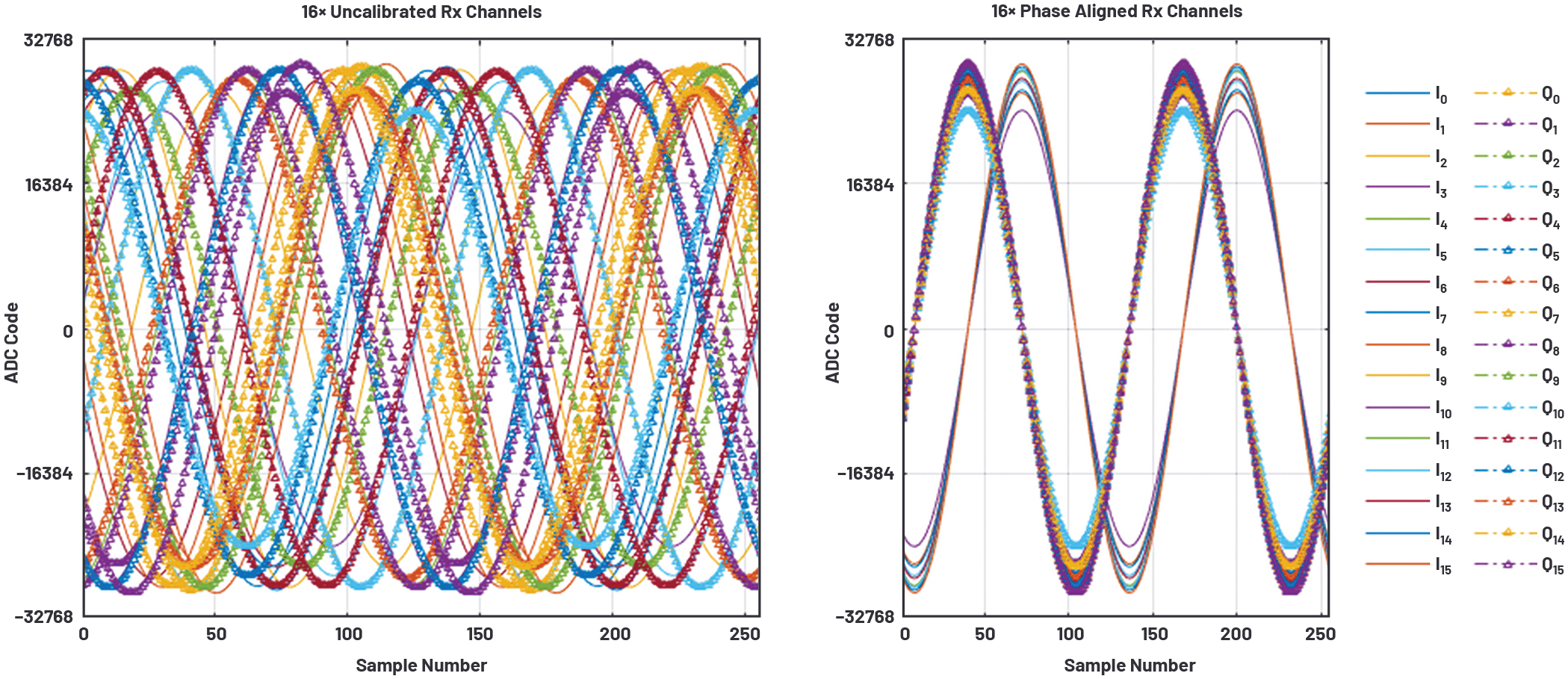
図3. 16個の受信チャンネルで同時に取得したI/Qデータ(左)。(右)は、DDCブロックの複素NCOに対して位相オフセットを設定し、位相のアライメントを行った結果です(振幅のアライメントは未実施)。
プログラムが可能なFIRフィルタ
NCOの出力に設けられた位相オフセット・ブロックは、単一周波数に対する位相のアライメントに使用できます。ただ、多くの場合、サブアレイのキャリブレーションでは、対象となる全周波数帯を対象として位相のアライメントを実施する必要があります。また、振幅のイコライゼーションと振幅(ゲイン)の平坦化も必要です。前者は、全チャンネルの信号振幅が共通のリファレンス・チャンネルに対して基本的に同一になるようにする処理です。後者は、全チャンネルの振幅応答が、周波数に依存して変化することがないようにするというものです。
広い帯域を対象として位相と振幅の補正を行うためには、多くの場合、別のDSPブロックが必要になります。そのDSPブロックが、FIR(Finite Impulse Response:有限インパルス応答)フィルタです2。FIRフィルタは、DSPにおいて多用されるデジタル・フィルタの一種です。フィルタの係数を変更することにより、入力されるデジタル信号の振幅と位相の応答を変化させることができます。係数の値を随時変更できるものは、プログラマブルなFIRフィルタ(pFIR)として知られています。pFIRを使えば、チャンネルごとに所望の振幅と位相の応答を得ることが可能です。
pFIRによる振幅のイコライゼーション、ゲインの平坦化
広い帯域を対象として振幅と位相のアライメントを行うと共に、ゲインの平坦化も実現したい場合には、図4のような回路を構成します。このシステムでは、デジタイザIC(MxFE:ミックスド・シグナル・フロント・エンド)「AD9081」を4個使用しています。AD9081は、送信/受信(Tx/Rx)用のアナログ・チャンネルを各4個、送信/受信用のデジタル・チャンネルを各8個備えています。このデジタイザICを4個使うことで、計16個の送信/受信用アナログ・チャンネル、計32個の送信/受信用デジタル・チャンネルを実現できます。各デジタイザICには、PLL(フェーズ・ロック・ループ)シンセサイザICを使用してコンバータ用のサンプリング・クロックを供給します。また、クロック・バッファICを使って、マルチチップの同期アルゴリズムに必要なデジタル・リファレンス・クロックとシステム・リファレンス・クロックを供給します1。このシステムは、Sバンドに対応して動作するように構成しています。NCOの周波数は、すべての送受信チャンネルで2.7GHzのアナログ信号を処理できるように設定しました。このプラットフォームでは、DACのサンプリング・レートを12GSPSに設定しており、送信チャンネルは第1ナイキスト・ゾーンで合成を行います。一方、ADCのサンプリング・レートは4GSPSであり、受信チャンネルは第2ナイキスト・ゾーンで信号を取得します。

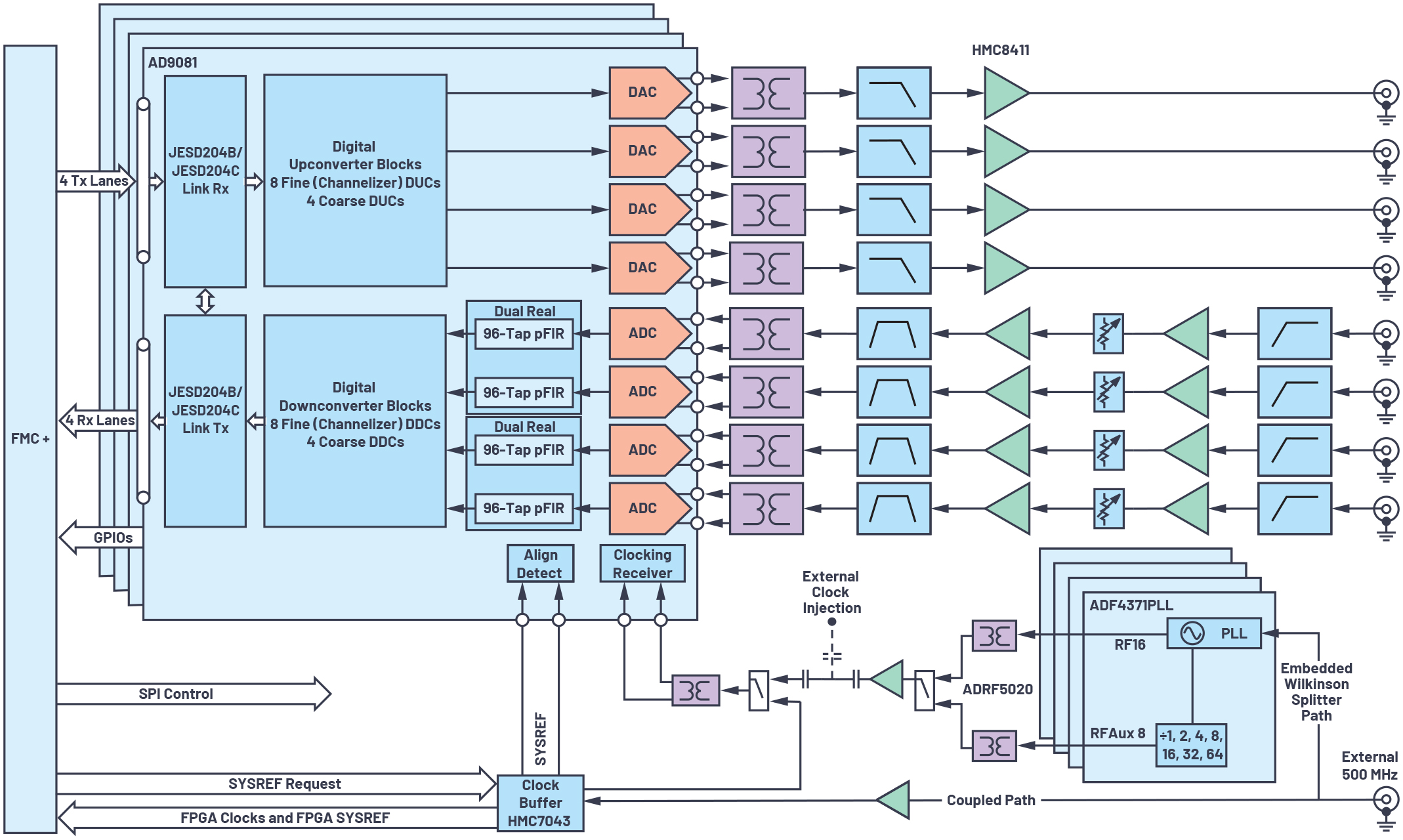
図4. システムのブロック図。マルチチャンネルの位相のアライメント、振幅のイコライゼーション/平坦化に対応します。
図5に、図4に示したシステムの外観を示しました。各16個の送信/受信チャンネルに対応するキャリブレーション用ボード(上)も組み合わせています。このボードを使用することで、全送信チャンネルの信号を結合し、それを個々の受信チャンネルにループ・バックします。それにより、全受信チャンネルで同時に信号を取得できるようにしています。このシステムのPLLシンセサイザは、自身の位相調整用ブロックを使用してアライメントされます。送信チャンネルと受信チャンネルでは、各DUC/DDCが備えるNCOの位相オフセット・ブロックを使用して粗いアライメントが施されます。その結果、図3に示したように、サブシステムではキャリブレーションの対象となる周波数で位相が粗くアライメントされます。ただ、振幅のアライメントはまだ実現できていません。本稿の実験では、上述したキャリブレーション用ボードを使用してシステムのアライメントを行います。なお、システム・キャリブレーション・リフレクタを使用すれば、同様の構成に対する処理をワイヤレスで実施することも可能です。この手法は、アンテナにおけるチャンネル間の問題を補償する際にも利用できます。

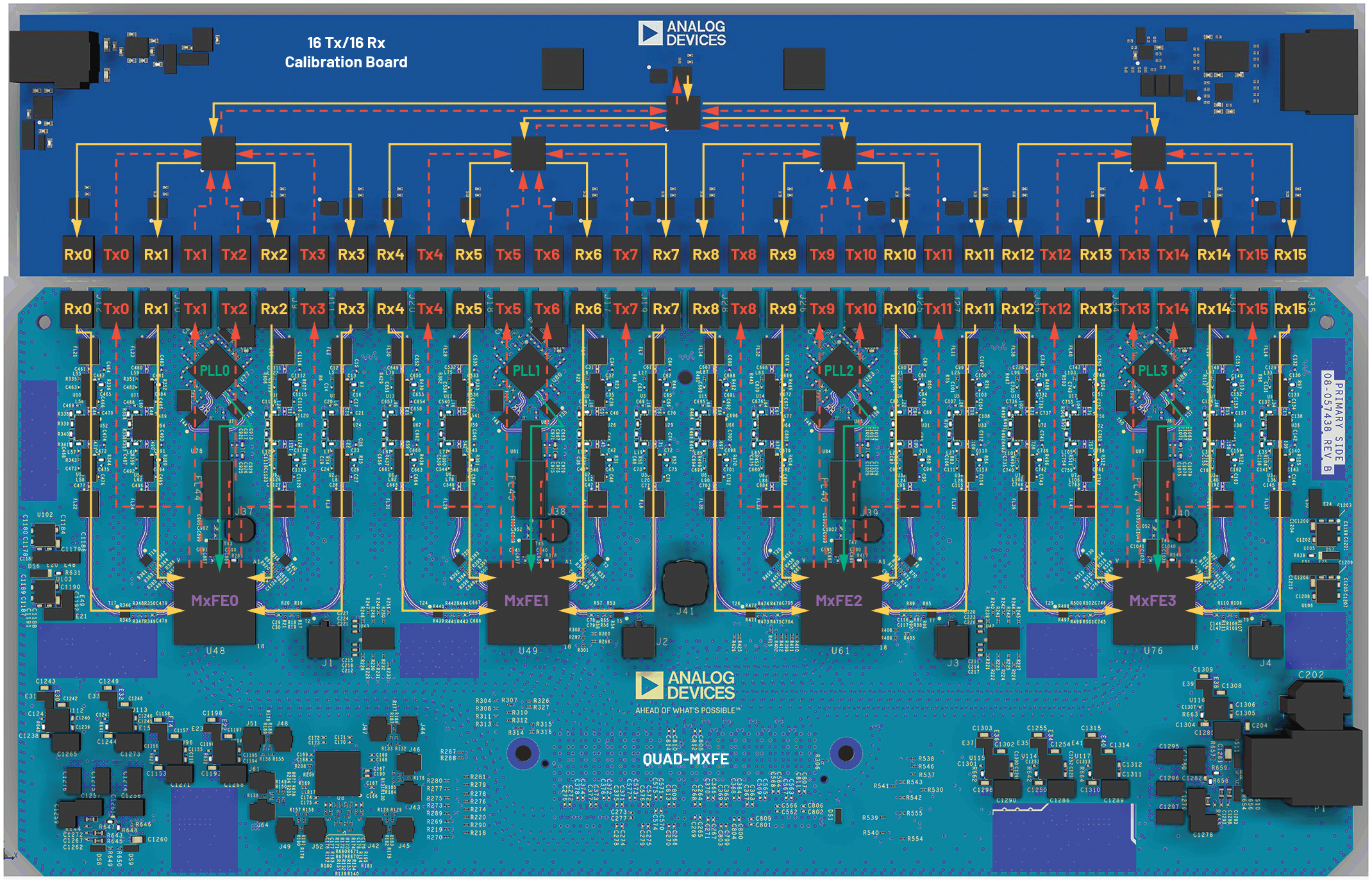
図5. 図4に示したシステムの外観。画像の下側の部分が、このシステムに相当するQuad-MxFE™です。このシステムには、画像の上側にあるキャリブレーション用ボードを接続しています。実験では、このキャリブレーション用ボードを使用して、すべての送信信号(赤)を結合します。次に、結合した信号を均等に分割し、各受信チャンネル(オレンジ)にループ・バックします。PLLシンセサイザの信号(緑)を調整することで、システムに意図的に熱を生じさせ、それによって起きた問題を補正するといったことも行えます。
図4に示したように、各ADCの出力には、96タップのpFIRが接続されています。それにより、サンプリング・レートに対応する全周波数範囲を対象として、各ADCのチャンネルの位相と振幅の応答をアライメントします。ここで、pFIRはADCとDDCブロックの間に配置されています。pFIRとDDCをつなぐデジタル・インターフェースのデータ・レートは、pFIRのレートとは異なります。したがって、pFIRを使用してチャンネルの振幅のアライメントを行うには、周波数変換とデシメーションに関する情報が必要になります。本稿の実験では、各ADCで実数値に相当する信号のサンプリングを行います。そのため、pFIRの入力は実数データになります。また、図4でデュアル実数というブロックで示しているように、このシステムでは、ADCのペアに1つのpFIRブロックを用意しています。そのため、2個のADCにI/Qの複合信号を入力し、システムのアライメントを実施することも可能です。
ここでは、各チャンネルの振幅のイコライゼーション/平坦化を行うために、各送信チャンネルに対してシステムのI/Q帯域幅内の全周波数を網羅するような広帯域のチャープ信号を入力します。このようにすることで、データ・レートの範囲全体を対象として、各周波数に対応する誤差応答を決定することができます。それに続き、デシメートしたI/Qのデータ・レートでベースラインのデータを取得します。本稿の実験では、ADCのサンプリング・レートを4GSPS、I/Qのデータ・レートを250MSPSに設定しています。したがって、第2ナイキスト・ゾーンから第1ナイキスト・ゾーンに折り返しイメージが生じます。そこで、送信用の各NCOの周波数は2.7GHz、受信用の各NCOの周波数は1.3GHzに設定しました。続いて、MATLAB®のシステム・インターフェースを使用し、ベースラインのデータを取得します。そして、各チャンネルの振幅と位相の誤差応答を計算します。その際には、すべての受信チャンネルで取得した信号の最大値がI/Qの全帯域で理想的な受信入力になるようにゲインを平坦化したRx0を基準として用います。図6は、16個のうち4個の受信チャンネルにおける位相と振幅の誤差応答を示したものです。図6(左)から、NCOの位相オフセットによって各受信チャンネルの位相の誤差はほぼ補正されているようです。しかし、図6(右)を見ればわかるように、システムには振幅の誤差が残っています。なお、残りの12個の受信チャンネルも同様の誤差応答を示します。また、受信信号の振幅がRx0と一致していないだけでなく、追加のキャリブレーション技術を適用しなければ、振幅の平坦性が得られないことにも注意が必要です。これらの問題は、振幅のイコライゼーションと平坦化の実験を行えるように、ADCのフロント・エンド回路に実装されているアナログ・フィルタを使って意図的に生じさせました。

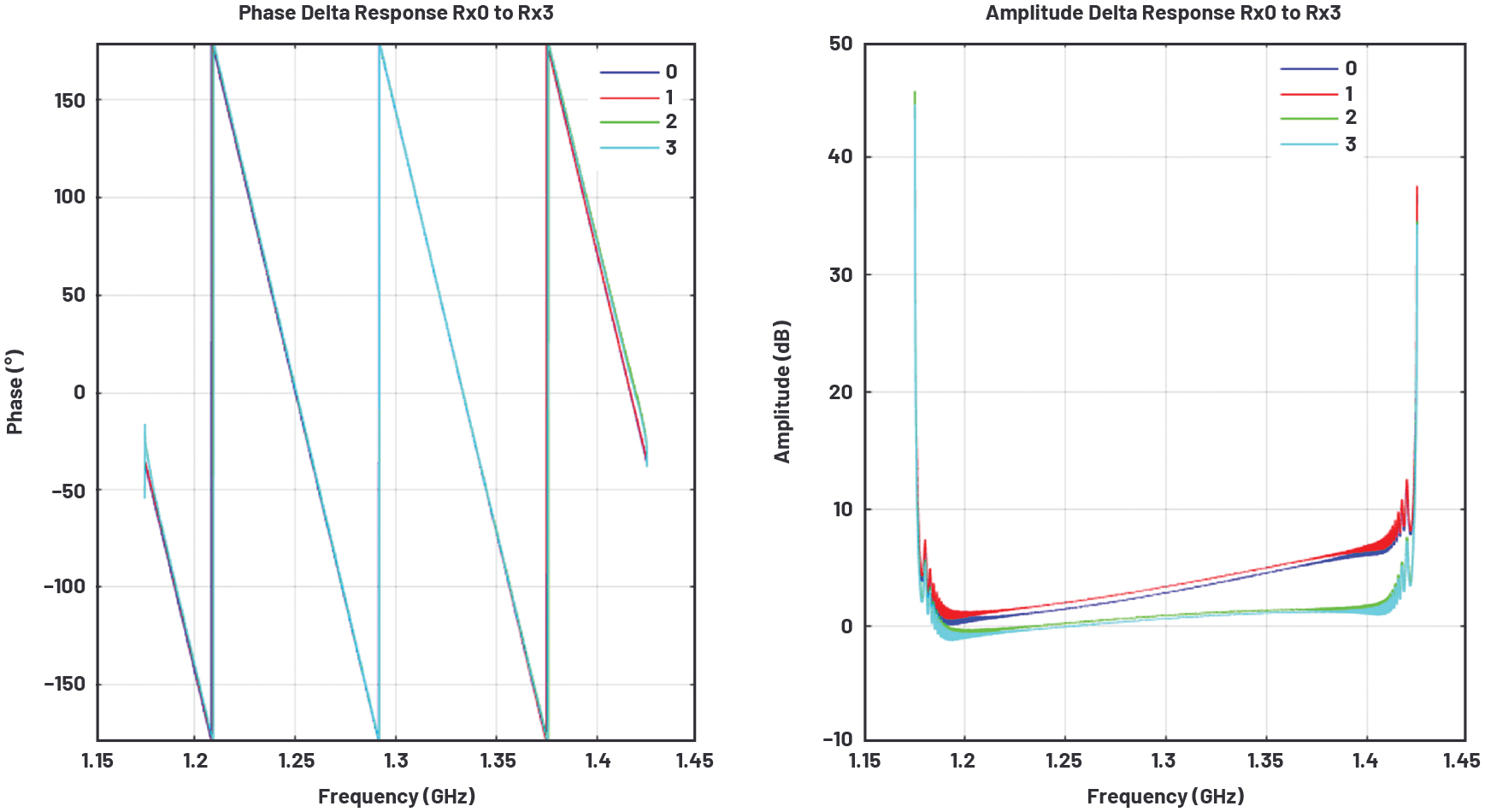
図6. 位相と振幅の誤差応答。ゲインの平坦化を実施した後のRx0を基準とし、各チャンネルの誤差を算出した結果です。この情報は、pFIRを設計する際に役に立ちます。
振幅のイコライゼーションと平坦化を実現するためには、平坦化を実施後のRx0を基準とし、各チャンネルの複素誤差に基づいて、任意の実数値の振幅と位相に対応可能な96タップのpFIRを設計します。その際には、対象となるI/Q信号の帯域が狭いほど誤差応答の重み付けを大きくするようにします。ただ、完全なpFIRを得たいなら、フル・レートのADCのナイキスト・ゾーンをカバーし、250MHzのサブバンドの外側では強制的にユニティ・ゲインの通過帯域応答が得られるように設計しなければなりません。本稿の例におけるpFIRの設計では、受信側のNCOの周波数(1.3GHz)を中心とする250MHzのサブバンドについては、ナイキスト・ゾーンの残りの部分よりも重み付けを大きくしています。このpFIRは、MATLABの「DSP System Toolbox」が備えるフィルタ設計機能を使って実現しました。同様のアルゴリズムは、フィールド・システム向けにハード化するデジタル回路にも適用可能です。図7は、16個のうち2個の受信チャンネル用に設計した96タップのpFIRの係数を示したものです。残る14個の受信チャンネルについても、同様に設計を行いました。図8に、16個の受信チャンネルに対応する各pFIRの振幅/位相応答を示しました。いずれも、ナイキスト・ゾーン全体にわたる特性を表しています。

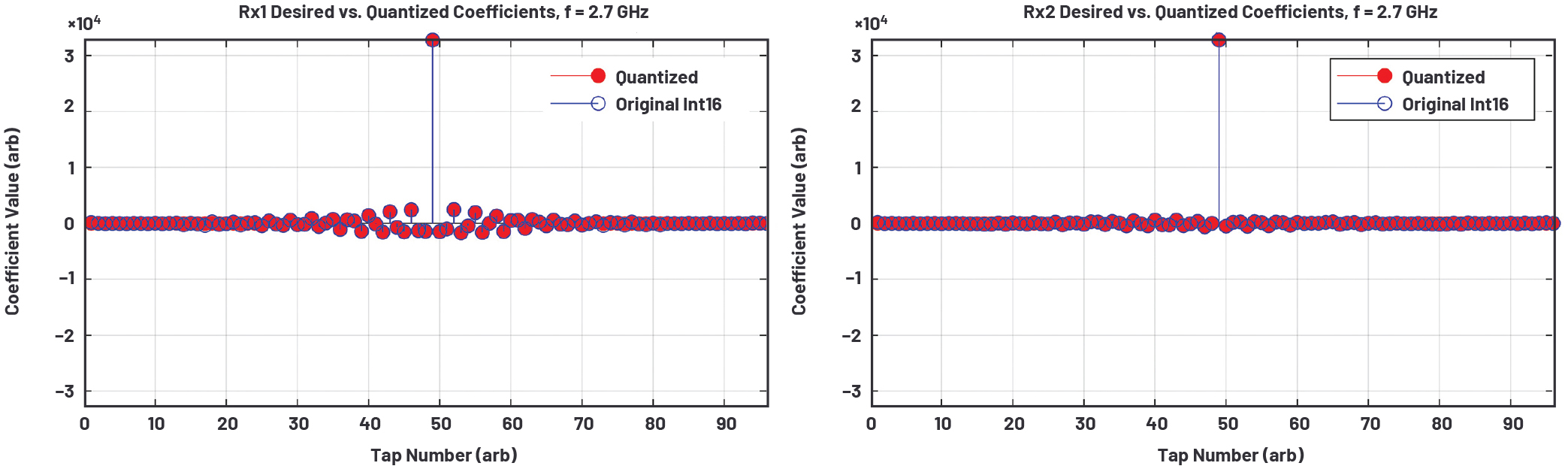
図7. 96タップのpFIRの係数。サブアレイ全体で振幅のイコライゼーションとゲインの平坦化を実現できるように設計します。

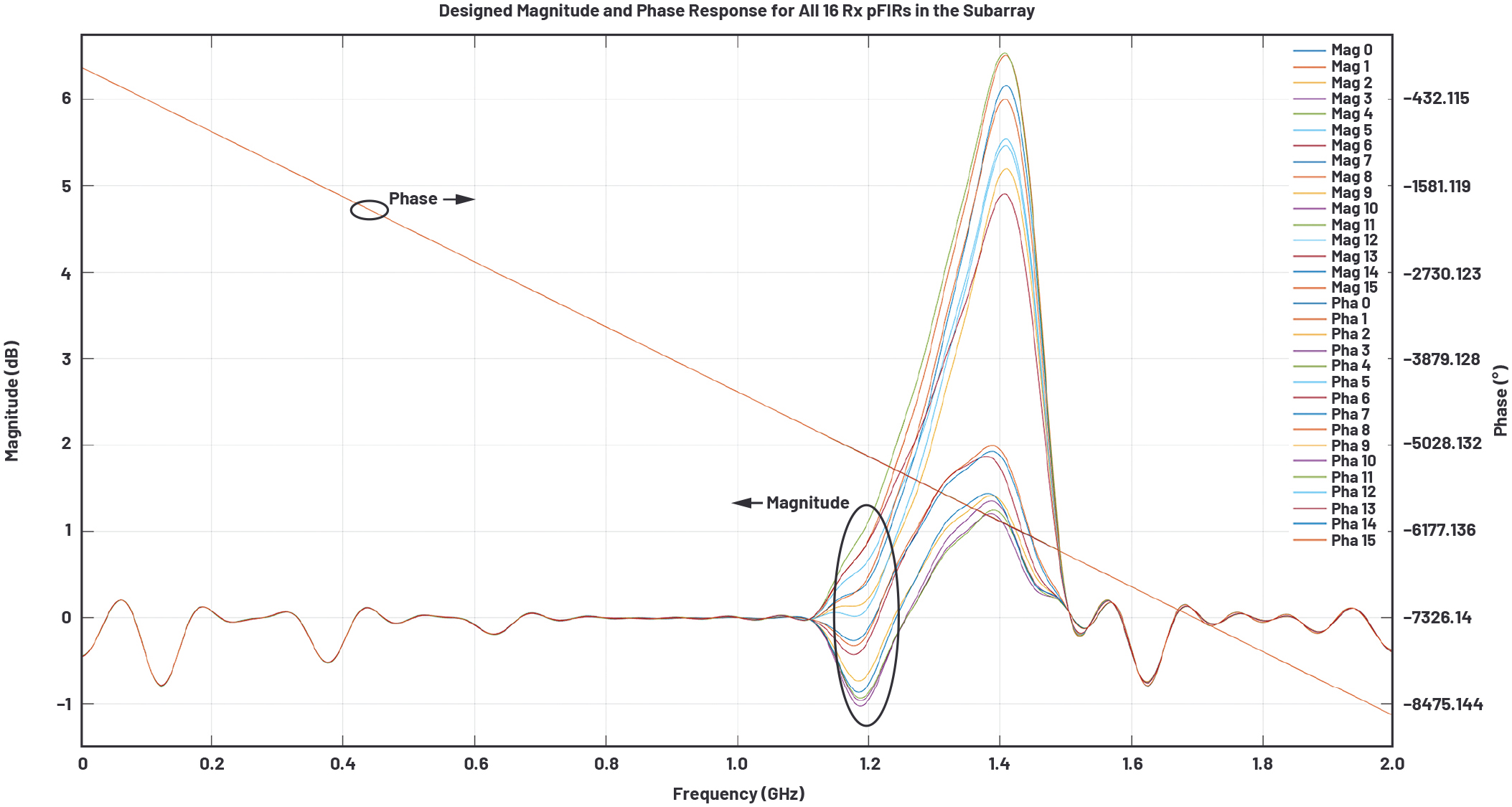
図8. 16個のpFIRの振幅/位相応答。各チャンネルにキャリブレーションを適用した結果を表しています。凡例の「Mag」は振幅、「Pha」は位相を表します。
通常、pFIRについては、0から1の間の連続値から成る係数空間で設計を行います。ただ、現実のハードウェアでは連続値の係数を量子化し、システムで使用できるビット幅内に収める必要があります。本稿で例にとっているシステムでは、pFIRの係数を可変ビット幅で表現できるようにしています。つまり、16ビットの係数もあれば、12ビットの係数もあります。更に、わずか6ビットの係数も存在するということです。なお、12ビットの係数は、16ビットの係数の隣に存在する必要があります。図7を見ればわかるように、16ビットが必要なのは値の大きい係数だけです。値の小さい係数には6ビットしか必要ありません。なお、理想的な係数を量子化する際には、必ず量子化誤差が生じます。そのため、この誤差を最小限に抑えられるように注意しなければなりません。本稿の例では、設計した係数が、利用可能な係数空間内に収まるようにしています。
量子化が完了したら、得られた係数を各チャンネルにロードします。この処理は、デジタイザICが提供するAPI(Application Programming Interface)によって実現します。本稿の例では、そのAPIを使用し、SPI(Serial Peripheral Interface)を介して各チャンネルの係数を変更しました。必要に応じ、専用のGPIO(General-purpose Input/Output)信号を使用して、係数一式をより迅速に変更することも可能です。
ここまでの作業を終えたら、pFIRの設計が有効であることを確認します。そのためには、pFIRをイネーブルにする前後の状態で受信データを取得/比較します。図9(上)に示したのは、pFIRをイネーブルにする前の結果です。振幅のイコライゼーションを実施する前の段階では、16個の受信チャンネルの振幅と位相は、対象となる周波数帯にわたって様々な値をとっている点に注目してください。また、8個の受信チャンネルにおける振幅は、他の8個とは異なるレベルの平坦性を示していることにも注意してください。一方、各受信チャンネルのpFIRをイネーブルにすると、図9(下)のような結果が得られます。ご覧のように、全受信チャンネルにおいて、I/Qの帯域幅全体にわたり振幅のイコライゼーションと平坦化が実現されています。また、位相のアライメントも適切に機能しています。実は、pFIRの設計をより精密に行えば、振幅と位相の応答を更に改善することも可能です。それについての解説は別の機会に譲ります。

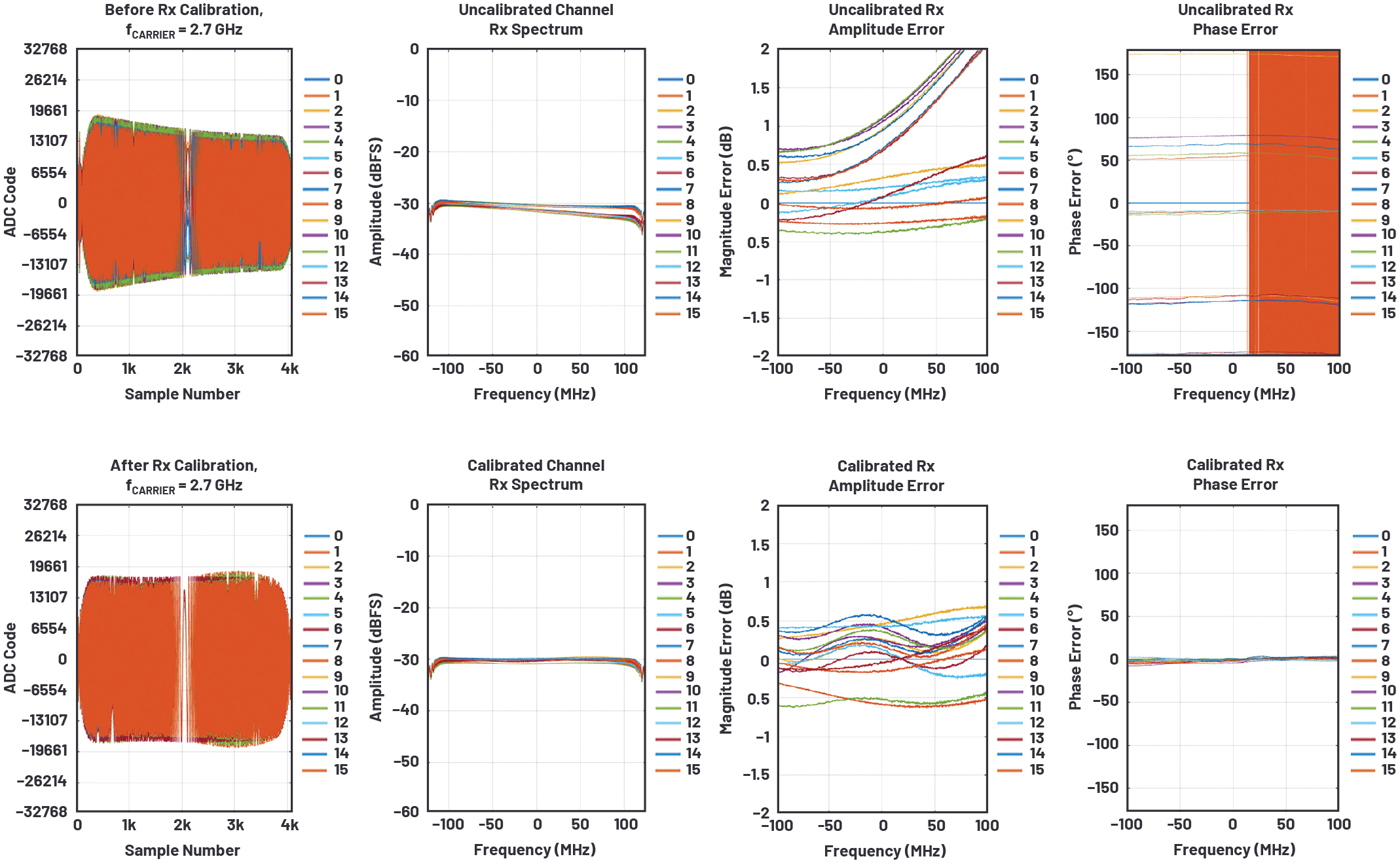
図9. pFIRの効果。各受信チャンネルにpFIRを実装することにより、Rx0を基準とした振幅のイコライゼーションと平坦化を実現することができます。
FPGAにFIRフィルタを実装する場合のリソース使用量
先述したように、ハード化されたpFIR(以下、pFIRという表記は、ハード化されたpFIRのことを意味するものとします)は、ADCのデータ・パスにおいてデシメーション段の前に配置されます。このpFIRにより、アプリケーションの柔軟性が大幅に向上します。しかも、デジタイザICにpFIRの機能をオフロードすることによって、FPGAのリソースの使用量を大幅に削減することができます。HDLで機能を記述してFPGAによって実装するのではなく、デジタイザICにpFIRを集積することにより、リソースの使用量の削減、設計の複雑さの軽減、消費電力の低減といった効果が得られます。
アプリケーションの分野によらず、リソースの消費量を削減するというのは重要なテーマです。pFIRを内蔵するデジタイザICを採用する場合、あらかじめ構築済みのフィルタを使用することになります。一方、FPGAにFIRフィルタを実装する場合には、DSPスライスを使用します。DSPスライスには、DSP機能を実現するためのFPGAファブリックのコンポーネントが含まれています。DSPスライスは、フリップフロップをはじめとする従来の論理ゲートとは異なるものであり、FPGAのリソース使用率(消費量)を算出する際にも、論理ゲートとは別扱いとなります。デジタイザICとFPGAのうち、どちらにFIRフィルタを実装するのかを決定する際には、FPGAにおけるリソースの使用率、特にDSPスライスの使用率が最も重要な要素になります。本稿では、pFIRとの比較の対象として、「Xilinx® Virtex® UltraScale+® FPGA VCU118」(以下、VCU118)を使用することにしました。このプラットフォームは、6840個のDSPスライスを備える「Virtex Ultrascale+ XCVU9P」(以下、XCVU9P)を搭載しています。このDSPスライスの数は、比較的多いと言えます。ただ、ファブリックに配置するフィルタの数を決める際には、チャンネル数も考慮しなければなりません。また、FIRフィルタの入力サンプリング・レート(入力データ・レート)が非常に重要な要素になります。
表1は、FPGA上にFIRフィルタを実装する際に必要なリソース量(推定値)についてまとめたものです。ここでは、デジタイザICのデータ・パス構成によって対応可能ないくつかのユース・ケースを前提としています。各条件において必要になるリソース量の推定値は、Xilinxの「LogiCORE™ IP FIR Compiler 7.2」のブロック・サマリに基づいています。このサマリについて確認するために、次のようなことを行いました。図10は、「MicroBlaze®」をベースとする設計の例です。これは「Xilinx Vivado™ Design Suite 2018.2」(以下、Vivado)を使って構築しました。この設計に、FIRフィルタを追加するケースを考えます。表1には、FIRフィルタの入力サンプリング・レートが250MSPS、1GSPSの場合の結果が示されています。これらのサンプリング・レートは、コンバータからのデシメートされたデータをFIRフィルタで処理するケースを想定した値です。また、表1には、サンプリング・レートが4GSPSの場合の結果も示されています。このサンプリング・レートは、データがデシメートされずにコンバータから直接入力されるケースを想定して設定しました。各FIRフィルタは250MHzで動作します。この値は、FIRフィルタがベースバンドのデータ・パス内に存在し、リロードが可能な16ビットの係数を96個含んでいる場合の動作を想定して設定しました。
| FIRフィルタの入力サンプリング・レート | FIRフィルタ1個あたりのDSPスライス数 | 必要なFIRフィルタの数 | 全FIRフィルタに必要なDSPスライスの総数 | XCVU9PのDSPスライスの使用率(母数は6840個)〔%〕 |
| 250MHz | 96 | 32 | 3072 | 45 |
| 1GHz | 384 | 32 | 12288 | 180 |
| 4GHz | 1536 | 16 | 24576 | 359 |

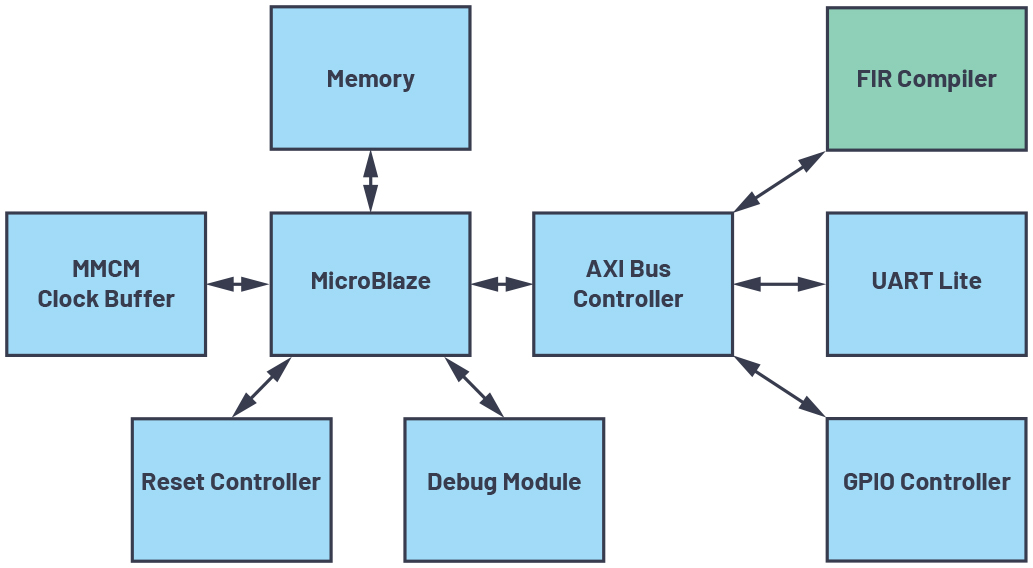
図10. MicroBlazeを使用した設計の例。1個のFIRフィルタを追加した場合のリソースの使用率を評価するために構築しました。
XCVU9Pのリソースの使用率を見れば、必要なフィルタをすべて実装するには、「XCVU13P」(1万2288個のDSPスライスを搭載)など、より大規模なFPGAを使用しなければならないことがわかります。4GSPSに対応するFIRフィルタを使用する場合には、少なくとも2個のXCVU13Pが必要になり、設計にかかるコストが増大します。それに対し、全16チャンネルに必要なすべてのpFIRを備えるデジタイザICを採用すれば、システム設計の複雑さが軽減されます。
FPGAにFIRフィルタを実装する場合には、もう1つの大きな懸念事項が浮上します。それは、DSPスライスの使用率が高くなることに伴い、設計が複雑になることです。ここで、FIRフィルタの構築方法について検討します。FPGA以外のICにFIRフィルタを実装する場合、同フィルタはチップ上の1つの位置に固定されることになります。ただ、係数や重み付けはデジタル的に変更できるので、比較的静的な実装だと表現することも可能です。一方、FPGA上にFIRフィルタを実装する場合には、チップ上の様々な領域に存在するDSPスライスを配線によって組み合わせることになります。そのため、より大規模なフィルタを構成する場合、FPGA上のより多くの領域を消費することになり、DSPスライス間の配線がより難しくなります。また、FIRフィルタの規模を大きくすると、FPGA上の他の部分の配線もより困難になります。条件によっては、タイミングが厳しい配線の実現は困難になるか、不可能になってしまう可能性があります。
デジタイザIC/FPGAにFIRフィルタを実装した場合の消費電力
マルチチャンネルのICでは、よりサンプリング・レートの高いコンバータが使われるようになっています。設計にDSPブロックを盛り込む場合には、システムの消費電力について分析を行う必要があります。従来、DSPブロックは、FPGAをはじめとするプログラマブル・ロジックICを使用して実装されていました。しかし、FPGAを使用すると、システムの消費電力が多くなりすぎてしまうことがあります。
ハード化DSPを使う場合とFPGAを使う場合を比較するために、VCU118に実装するいくつかの単純な回路を設計しました。それらを使って、いくつかの現実的な条件下でFPGAベースのFIRフィルタが消費する電力量を確認しました。VCU118を選択したのは、Xilinxが直接提供/サポートしている評価システムの中で、実験を行った時点で最も多くのDSPを搭載していたからです。VCU118をベースとし、FIRフィルタの入力サンプリング・レートごとにVivadoのプロジェクトを2つ作成しました。1つはフィルタを実装する場合に対応しており、もう1つはフィルタを実装しない場合に対応しています。サンプリング・レートが250MHz、1GHzという条件に対しては、図10に示したのと同様の設計に8個のFIRフィルタを追加しました。それに対し、サプリング・レートが4GHzという条件では、リソースの使用率が非常に高くなります。そのため、追加するFIRフィルタの数は2個に抑えることにしました。各フィルタへの入力データは、「Xilinx LogiCORE DDS Compiler 6.0」の出力ブロックを使用して生成します。合成の完了後には、RTLコードにFIRフィルタ用のコードが含まれていることを確認しました。また、それらが最適化されていないことも確認しました。このような確認作業も、実験においては重要な要素です。各サンプリング・レートに対応する比較用の設計として、FIRフィルタを含まない回路も用意しました。それらの回路は、FIRフィルタだけを削除し、他のIPブロックはすべてそのまま残しておくという方法で構築しました。
実装が完了したところで、システムを起動し、電流を測定しました。その結果を基に相対的な電力量の差を求めることにより、FIRフィルタを追加することで発生する消費電力の量を明らかにしました。表2は、FIRフィルタによって消費される電力量についてまとめたものです。次に、システムに必要な全FIRフィルタで消費されるトータルの電力量を算出(外挿)しました。実験では、サンプリング・レートが250MHz、1GHzの条件では8個、4GHzの条件では2個のFIRフィルタについてデータを収集しています。それらのデータを基に、実際のシステムに必要な全FIRフィルタを実装した場合の消費電力を推定したということです。FIRフィルタとしては、VCU118には実装できず、デジタイザICになら実装可能な様々な構成が考えられます。そうした拡張を図る際、ここで算出した消費電力の値を基本単位として利用することができます。実際のシステムの消費電力が線形に増加する可能性は低いので、FPGAにとっては比較的公平であるか、おそらくは有利な結果になると考えられます。最後に、上記の結果を「Xilinx Power Estimator(XPE)」3で生成した、様々なFIRフィルタの消費電力(見積もり値)と比較しました。得られた見積もり値は、上記の推定値と比べてはるかに大きくなります。これは、リソースの使用率が高くなるに連れ、消費電力が非線形に増加することを示唆しています。
| FIRフィルタの入力サンプリング・レート | FPGAに実装しなければならないFIRフィルタの数 | FPGA上のFIRフィルタ(1個)の消費電力(測定値)〔W〕 | FPGA上の全FIRフィルタの総消費電力(計算値)〔W〕 | FPGA上のFIRフィルタ(1個)の消費電力(XPEで見積もり)〔W〕 | 厳しい条件下におけるFPGA上の全FIRフィルタの総消費電力(XPEで見積もり)〔W〕 | デジタイザICのpFIR(1個)の消費電力(測定値)〔W〕 | デジタイザICの全pFIRの総消費電力(測定値)〔W〕 |
| 250MHz | 32 | 0.075 | 2.40 | 0.391 | 13 | X | X |
| 1GHz | 32 | 0.22 | 7.04 | 1.564 | 50 | X | X |
| 4GHz | 16 | 0.81 | 12.96 | 6.254 | 100 | 0.405 | 6.48 |
続いて、FPGAに実装したFIRフィルタとデジタイザICのpFIRの消費電力を比較します。具体的には、FPGA向けに設計した単純なフィルタの消費電流を測定した結果と、デジタイザICのpFIRを使用するマルチチャンネル・システムの実際の消費電流を比較しました。デジタイザICを使用したシステムの総消費電力(すべてのフロント・エンド回路とクロック回路を含む)は、pFIRがイネーブルになっていない状態で約98.40Wでした。一方、16個のpFIRをすべてイネーブルにすると、総消費電力は約104.88Wになります。したがって、受信チャンネルで使用する16個のpFIRの消費電力は約6.48Wです。この例の場合、pFIRはADCから直接データを受信するので、ADCのサンプリング・レートと同じレート(4GSPS)で動作する必要があります。
上記の消費電力と、4GSPSで動作する16個のFIRフィルタをFPGAに実装した場合の消費電力を比較するのは、少し無理があります。Virtex Ultrascale+シリーズのFPGAを1個だけ使用するとしたら、リソースの使用率があり得ないほど高くなるからです。そこで、FPGAに実装した250MSPSのFIRフィルタと4GSPSのpFIRの比較を行ってみることにしました。その結果を、表2と図11にまとめています。FPGAに実装した32個(I/Q用に各16個)のFIRフィルタの消費電力は、2.40Wとなりました。FPGAに実装したFIRフィルタは、デジタイザICのハード化DSPと比べて1/16の速度で動作させました。それでも、FPGAに実装したFIRフィルタは、pFIRを備えるデジタイザICの0.37倍の電力を消費しています。また、FPGAに実装した32個のFIRフィルタを1GSPSで動作させた場合と、pFIRを4GSPSで動作させた場合の比較も行いました。その場合、FPGAに実装したFIRフィルタは、pFIRの1/4の速度で動作させているのに、約7.04Wの電力を消費します(既にpFIRの消費電力を上回っています)。更に、FPGAに実装した16個のFIRフィルタを4GSPSで動作させた場合と16個のpFIRを4GSPSで動作させた場合を比較すると、このシステム構成では前者は2倍の電力を消費します。まとめると、図11に示したとおり、デジタイザICのpFIRの消費電力は、FPGAに実装したFIRフィルタの消費電力よりも少ないことがわかります。また、pFIRを使用することにより、FPGAのDSPスライスの使用率を下げることができます。加えて、設計の複雑さを緩和すると共に、トータルの消費電力を削減することが可能になります。なお、250MSPSのFIRフィルタに合わせてデータ・レートを下げることができない場合には、より高いデータ・レートのFIRフィルタを使用することになるでしょう。その場合、より広い帯域幅に対応するアプリケーションを実現できるかもしれません。

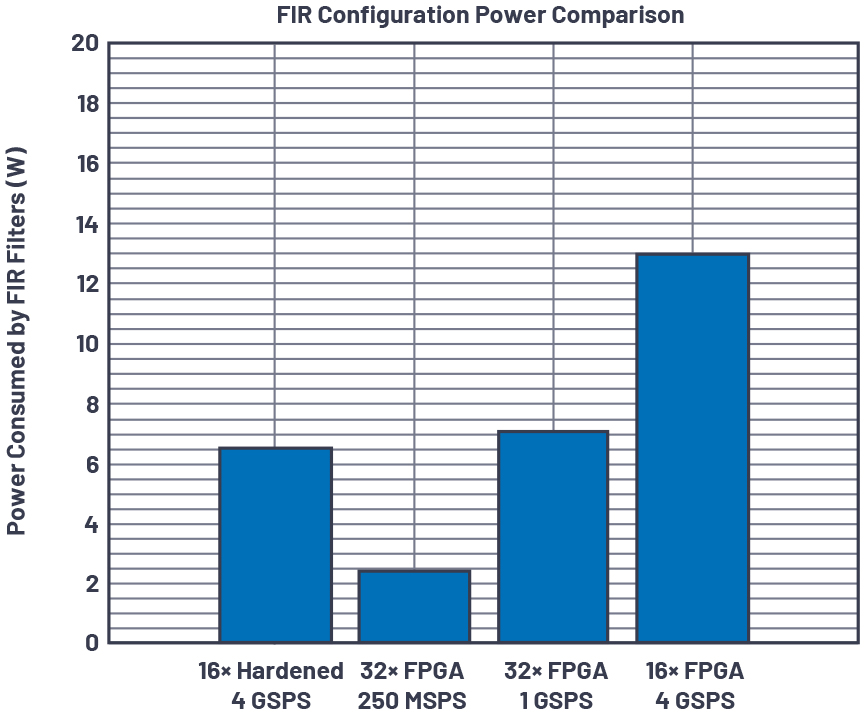
図11. FPGA上のFIRフィルタとハード化DSPの消費電力。デジタイザICのハード化DSPを使用すると、システム・レベルの消費電力を削減することができます。
最後に、スケーラビリティについて検討しましょう。AD9081のようなデジタイザICが備えるハード化DSPを活用する場合、スケーラビリティについてはどのように考えればよいのでしょうか。多くの最終的なシステムにおいて、実際に16個ものチャンネルが存在するのは、小さなサブアレイの中だけかもしれません。AD9081のpFIRのようなハード化DSPを活用することで、いくつかのメリットを得ることができます。FPGAのリソースを追加してバックエンドの処理を拡張する場合と比べると、規模の面で柔軟性の高いソリューションが得られるからです。また、シグナル・チェーンもはるかにシンプルになります。多くの場合、この種の議論は、最終的にはすべてのデータを単一のFPGAに集約しなければならない中央処理モデルのシステムを対象として行われます。その場合、チャンネル数を増やすためにフィルタ機能を内蔵するコンバータを追加すると、より多くのSERDES(Serializer Deserializer)レーンが必要になります。しかし、FPGAのリソースを増やす必要はないので、アーキテクチャの観点からは管理が容易になります。ハード化DSPを利用できない場合、アプリケーションに必要なリソースを確保するためには、複数のFPGAを使用しなければなりません。そうすると、複雑さが大幅に増してしまいます。
まとめ
本稿では、デジタイザICのハード化DSPを利用するシステムのメリットについて説明しました。この種のデジタイザICを使用すれば、フェーズド・アレイ、レーダー、衛星通信、電子戦などのシステムにおいて、複数のチャンネルの振幅/位相に対するイコライゼーションを実現できます。デジタイザICに集積されたpFIRとDUC/DDCが備えるNCOの位相オフセット・ブロックを使用すれば、FPGAでそれらのDSPブロックを実装することなく、広帯域に対応する複数チャンネルのイコライゼーションを実現可能です。本稿で使用したプラットフォームは「Quad-MxFE」と呼ばれています(図12)4。Quad-MxFEは、「ADQUADMXFE1EBZ」という品番で購入できます。このプラットフォームでは、サブアレイの設計における中核としてAD9081(MxFE)を使用しています。HDLコードのサンプル、MATLABスクリプト、ユーザ用のドキュメントについては、ADQUADMXFE1EBZのWikiページを参照してください。また、各16の送信/受信チャンネルに対応するキャリブレーション用ボード(ADQUADMXFE-CAL)も提供されています。計測機器や5Gの分野におけるサブアレイのテストや評価、基地局の開発にも、本稿で示した手法を活用できる可能性があります。


図12. Quad-MxFEの外観
著者について
この記事に関して
産業向けソリューション
























