Data Loader Design for MAX78000 Model Training
Abstract
The MAX78000, Artificial Intelligence Microcontroller with Ultra-Low-Power Convolutional Neural Network Accelerator, can effectively run artificial intelligence models on the chip. Users should first develop a neural network model, using Analog Devices’s development flow on PyTorch. The MAX78000 synthesizer tool then accepts the PyTorch checkpoint and the model description in the YAML format to automatically generate the C code to be compiled and executed on the MAX78000. One of the essential software components used in the model development phase is the data loader, which is responsible for application-specific data preparation tasks. This document describes principles and design considerations on a data loader implementation when preparing application-specific training and validation/test set entities suited for the MAX78000 model training.
Introduction
In the application development cycle, one of the first steps is to prepare and preprocess the available data to create training and validation/test datasets. In addition to the usual data preprocessing, several hardware constraints have to be considered to run the model on the MAX78000.
The primary responsibilities of a data loader can be summarized as follows:
- [optional] Downloading the input and label data from the original resource into the data path provided by calling Analog Devices' CNN training tool (training repository/train.py).
- Reading raw input data from the data path specified (csv/binary file/s, folder/s with or without hierarchies etc.).
- Reading raw label/annotations in the data path provided (csv/binary file/s, folder/s with or without hierarchies etc.).
- [optional] Applying data preprocessing steps like augmentation, data cleaning, etc.
- Applying the required data type and range transformations on both input data and labels.
- Performing training and test/validation splits.
- Providing a data loader method and a definition dictionary compatible with the MAX78000 model training tool.
- [optional] Keeping processed data entities on disk for ease of future access.
- [optional] Applying the above steps for each different dataset variation that can be generated from the same original data source.
- Providing two PyTorch datasets for training and test data.
The following sections provide instructions on creating an efficient data loader to satisfy the required functionality and conveniently integrate the training tool.
Figure 1 shows the main flow of a data loader implementation abstractly. The details are presented in the following sections.
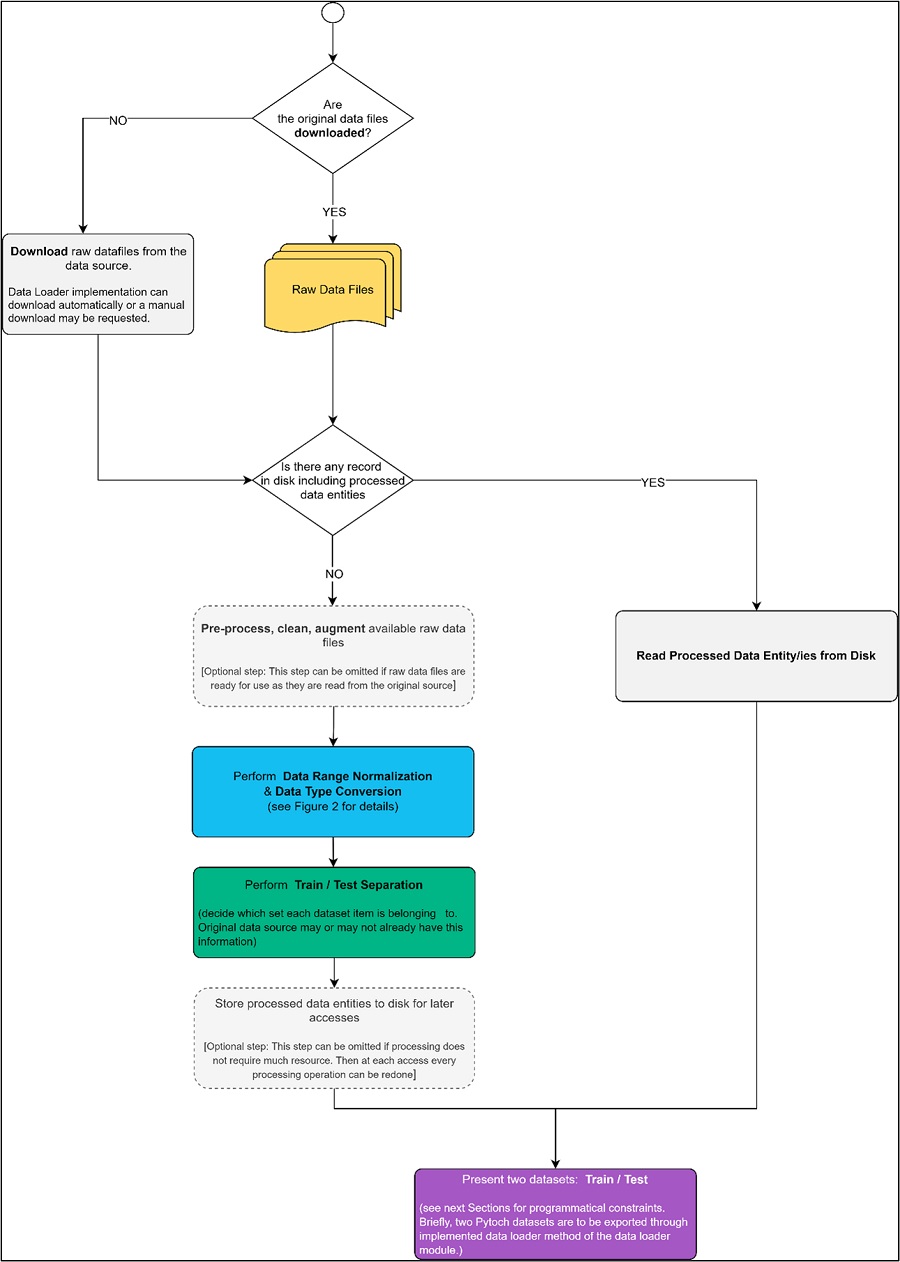
Figure 1. Main Flow of Data Loader Module.
Design Principles for a Custom Data Loader Implementation
One of the primary responsibilities of data loader implementation is the data range adjustment and data type management before a dataset entity can be fed to the CNN model. These operations are summarized in Figure 2 and are detailed in the following sections.
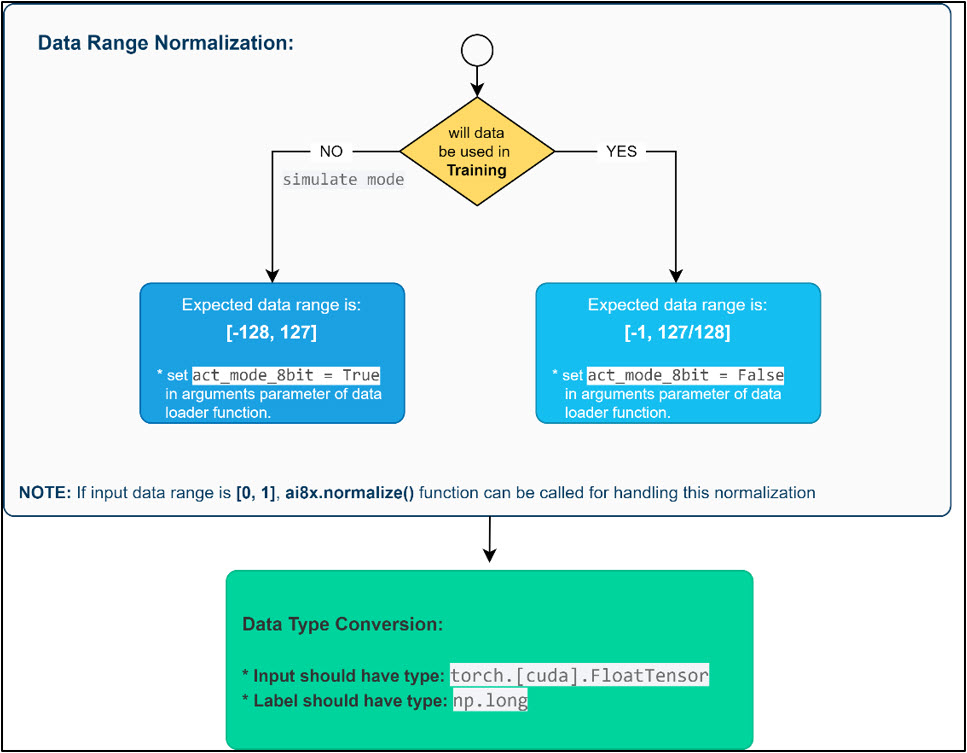
Figure 2. Data Range Normalization and Type Conversion.
Expected Data Range
For training, input data is expected to be in the range 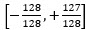 . When evaluating quantized weights, or when running on hardware, input data is instead expected to be in the native MAX7800X range of [-128, +127].
. When evaluating quantized weights, or when running on hardware, input data is instead expected to be in the native MAX7800X range of [-128, +127].
As described in the following sections, the data loader function takes the data path and some arguments as input arguments. The arguments field includes two required fields, act_mode_8bit and truncate_testset. When set to True, the first argument refers to the case normalization should be done correctly for the native MAX7800X range, i.e., to range [-128, +127]. When set to False, the normalization should be in the range of for training.
If the available data is in the range of [0 1], e.g., as in PIL images, the data loader can directly call the ai8x.normalize() function to normalize the data to the two supported data ranges using the provided args argument:
class normalize:
"""
Normalize input to either [-128/128, +127/128] or [-128, +127]
"""
def __init__(self, args):
self.args = args
def __call__(self, img):
if self.args.act_mode_8bit:
return img.sub(0.5).mul(256.).round().clamp(min=-128, max=127)
return img.sub(0.5).mul(256.).round().clamp(min=-128, max=127).div(128.)
If the available data range is [0 255], it needs to be divided by 256 to bring it to the [0 1] range before calling the ai8x.normalize() function.
Note: The device setting method ai8x.set_device of the ai8x module also accepts a related parameter simulate: True for the training case (act_mode_8bit = True) and False for the evaluation of quantized model or running on hardware that also initializes act_mode_8bit = False. This method is used by training scripts with proper argument management, but if one calls the function externally, the simulate parameter should be set correctly.
When running inference on the MAX7800X hardware, it is essential to take the native data format into account, and it is desirable to perform as little preprocessing as possible during inference.
Data Types
Data sources may have the raw data files in various formats and values in different ranges. The dataset class and data loader function are responsible for handling the necessary transformations.
The data loader function should return training and test dataset tuples of the data class. The type castings and transformations are usually handled inside the __get_item__ function, which should return a tuple of data and label for the specified indexed data entity. The data item should have the type: torch.[cuda].FloatTensor of shape torch.Size (datasets dictionary's related entries 'input' field).
The label dimension can vary for the problem type or input data shape. Each label type should be cast to np.long for proper training loss calculation in the training script.
After completing all data augmentation and preprocessing tasks and normalizing the data range to [0 1], the ai8x_normalize should be used for proper further normalization and torchvision.transforms.ToTensor then can be used to perform type translation.
Note: To get torch.[cuda].FloatTensor, numpy array has to be cast to float32 beforehand.
The torchvision package includes various preprocessing transformations such as random crops for PIL images that can be utilized according to the application's needs. The torchvision package's Compound transformations can be utilized by the data class to apply several transformations sequentially, such as ToTensor transformation and ai8x_normalize whenever data entries are accessed.
Storage of Data Entities
Generally, there are two ways to store the dataset entries; the entire dataset entries can be stored in memory or read from disk as they are accessed using the __getitem__ method. The essential decision factor is the size of the dataset and the size of each entity. When the dataset size is too large to fit in the memory (after the preprocessing and augmentation tasks are handled in the initialization function), all dataset entries can be saved to the disk and read individually from the disk at each latter access. While keeping the data entries in the memory speeds up the data access, memory limitations may prevent using the memory-based approach for all cases.
Note: Even if the memory-based approach is employed, the preprocessed and augmented data entries are recommended to be written to the disk as they are performed only once. Then, at each data class instance generation, a batch reading of all data into memory can be performed.
Table 1 summarizes some measurements for the two data loader implementation options for the same data source. As can be seen from the first row, the disk storage approach enables the processing of more images. The memory budget is the factor limiting the number of processed images. The dataset generation time is long in both approaches, as the first one also handles the preprocessing, augmentation, etc., steps followed by writing all available data to the disk. The memory-based approach takes much longer to generate datasets in later times because the object creation requires batch reading of a large file from disk into memory. Whereas in the second approach, where each dataset item is saved independently, both dataset object creation and entity retrieval by the __getitem__ method take little time. Memory consumption of the first approach is high as it keeps all dataset entities in memory. In terms of disk usage, the first approach usually uses a single file of all data entries, and the second approach uses separate files for each. That should result in an approximately similar disk budget.
Note: In Table 1, the disk space of the first approach is much smaller due to the decreased number of processed images. The disk approach's only drawback is that it increases training time as each data entry read is done as a separate disk operation.
| Data Loader with images stored in memory with images stored in memory | Data Loader with images read from disk | |
| Number of Images that can be processed | 20 000 * 1 = 20000 | 34 426 * 3 = 103 278 |
| Dataset generation time – first run | 30 min | 60 min |
| Dataset generation time – subsequent runs | 15 min | Instant |
| Runtime memory consumption peak | ~55 GB | ~5 GB |
| Disk consumption | ~50 GB | ~ 240 GB |
| Training time single epoch | 60-62 seconds | 1450 seconds |
Programming Principles for a Custom Data Loader Implementation
The data loader module is to be implemented in PyTorch and is expected to have at least the following three components:
- Dataset class definition. Example: class AISegment(Dataset)
torch.utils.data.Dataset is an abstract class that the custom dataset implementation class should inherit. For a tutorial on customized data loader implementation in PyTorch, see [1].
- __len__ method should be overridden so that len(dataset) returns the size of the dataset.
- __getitem__ should also be implemented to support the indexing such that dataset[i] can be used to get the ith sample. For MAX78000 applications, this method should return a tuple of data and its corresponding label.
- __init__ function parameters and contents can be customized as much as required by the application needs. The first two parameters are usually the data root path and type (test or train), as exemplified in the several data loader implementations in the MAX78000 training repository datasets folder. However, one can alter the order or the naming of these parameters as long as the data loader function presented in the following item and provided as an outside communication point is fixed and performs the desired operations.
- Data loader function: The signature of this function should not be modified. The first input is a tuple of the specified data directory and the program arguments. The two leading bool inputs specify whether training and/or test data should be loaded.
The program arguments have two critical fields related to the data class implementation; act_mode_8bit and truncate_testset. The first one refers to the normalization type (for more details, see the section Expected Data Range), and the second one is for truncating the test set into a single element set.
Example: def AISegment352_get_datasets(data, load_train=True, load_test=True).
- datasets dictionary includes available data loader functions. Neither the dictionary name nor the key values should be altered, and only the values should be adjusted according to the customized dataset implementation. Each variant of the same data source can exist as a separate element in this dictionary.
Example:
- 'name' key's value enables the Analog Devices CNN training tool (training repository/train.py) to find the dataset when provided with --dataset argument. Therefore, this field's value should be unique among the custom datasets.
- 'input' key's value is the dimension of the input data. The first dimension is passed as num_channels to the model, whereas the remaining dimensions are passed as dimension. For example, 'input': (1, 28, 28) passes to the model as num_channels=1 and dimensions=(28, 28). One-dimensional input uses a single "dimension", for example 'input': (2, 512) passes to the model as num_channels=2 and dimensions=(512, ).
- 'output' key's value specifies the available class types for a classification problem. This key's value can also be defined using string literals.
Example: 'output': ('background', 'portrait'). - 'weight' key's value specifies the weights of each data entity with reference to class labels. It is an optional field that is "1" for all if not be provided.
One can solve the class imbalance problem in the training dataset by providing inversely proportional weights to each class using the number of samples available. The training script therefore pays more attention to the samples that have a low frequency. - The optional regression can be set to True to automatically select the training scripts's --regression command-line argument.
Note: When the number of classes is given as 1, the training script automatically sets regression. Example: 'output': ('id'), 'regression': True.
datasets = [
{
'name': 'AISegment_80',
'input': (3, 80, 80),
'output': (0, 1),
'weight': (1, 1),
'loader': AISegment_get_datasets,
},
{
'name': 'AISegment_352',
'input': (48, 88, 88),
'output': (0, 1),
'weight': (1, 1),
'loader': AISegment352_get_datasets,
}
]
Sample Data Loader
The MAX78000 training repository datasets folder includes several different data loader implementations, for more details, see [2]. In this section, a customized data loader is presented to exemplify all the mentioned principles. The portrait segmentation dataset is used for this purpose, for more details, see [3]. This dataset source includes 34,427 human portrait images with a 600 × 800 resolution, in red, green, and blue (RGB) color format, and the same number of label images with respective masks of the same size in red, green, blue, and alpha (RGBA) format.
Initialization
The designed data loader module's first component is the data loader class with the initialization function below. The details on the generation of dataset information data frames are skipped. In short, these lines include some path processing codes to keep the original image path, original matting file path, crop idx, and the pickle file path for a dataset entry to be saved into. Other than these path generation parts, the main functionality of the initialization function is to keep the provided parameters and arrange some local variables accordingly (e.g., train or test dataset information data frame) and generate dataset entities.
For the first initialization call, all data processing tasks are handled using the __gen_datasets__ method, and pickle files are generated for each dataset item and stored on disk to be read at each data access.
class AISegment(Dataset):
…
def __init__(self, root_dir, d_type, transform=None, im_size=[80, 80], fold_ratio=1):
…
self.d_type = d_type
self.transform = transform
self.img_ds_dim = im_size
self.fold_ratio = fold_ratio
# Generate and save dataset information file if not already available
# Training and Test split is also performed here using the hash of file names (all three cropped images should fall into the same set)
# Information data frames include raw data path, raw label path, crop idx, pickle file path, etc. for each data entity
…
# One of the created data frames is selected from: train_img_files_info & test_img_files_info
if self.d_type == 'train':
self.img_files_info = train_img_files_info
elif self.d_type == 'test':
self.img_files_info = test_img_files_info
else:
print('Unknown data type: %s' % self.d_type)
return
# Create and save pt files for each data entity (if not available before)
self.__create_pt_files()
self.is_truncated = False
def __create_pt_files(self):
if self.__check_pt_files_exist():
return
self.__makedir_exist_ok(self.processed_train_data_folder)
self.__makedir_exist_ok(self.processed_test_data_folder)
self.__gen_datasets()
Data Augmentation
The gen_datasets method handles all required preprocessing, augmentation, and pre-normalization steps. The steps implemented are as follows:
- Three square images are cropped from the original image (as the U-Net model utilizes square images).
- Cropped images and matting images are down-sampled to 80×80 or 352×352 according to the provided dataset parameters.
- Corresponding matting images are converted to binary 'Background' or 'Portrait' labels.
- Images are folded if required (352×352 images are folded into images of size 88×88×48).
- Images are scaled by 256 before saving, as compound transformers expect images in the range [0 1], but the original images are RGB and have values in range [0 255].
The image cropping principle is shown in Figure 3.
Figure 4 includes three sample training images constructed from the same original image.

Figure 3. Sample Data Loader – Data Augmentation: Three square images are cropped from the original image.

Figure 4. Three images (and corresponding matting images) of size 600 × 600 are cropped from the original image (800 × 600).
The gen_datasets method is implemented as follows:
def __normalize_image(self, image):
return image / 256
def __gen_datasets(self):
# For each entry in dataset information dataframe
for _, row in tqdm(self.img_files_info.iterrows()):
img_file = row['img_file_path']
matting_file = row['lbl_file_path']
pickle_file = row['pickle_file_path']
img_crp_idx = row['crp_idx']
img = Image.open(img_file)
lbl_rgba = Image.open(matting_file)
vertical_crop_area = AISegment.img_dim[0] - AISegment.img_crp_dim[0]
step_size = vertical_crop_area / (AISegment.num_of_cropped_imgs - 1)
# Determine top left coordinate of the crop area
top_left_x = 0
top_left_y = 0 + img_crp_idx * step_size
# Determine bottom right coordinate of the crop area
bottom_right_x = AISegment.img_crp_dim[0]
bottom_right_y = top_left_y + AISegment.img_crp_dim[0]
img_crp = img.crop((top_left_x, top_left_y, bottom_right_x, bottom_right_y))
img_crp_lbl = lbl_rgba.crop((top_left_x, top_left_y, bottom_right_x, bottom_right_y))
img_crp = img_crp.resize(self.img_ds_dim)
img_crp = np.asarray(img_crp).astype(np.uint8)
img_crp_lbl = img_crp_lbl.resize(self.img_ds_dim)
img_crp_lbl = (np.asarray(img_crp_lbl)[:, :, 3] == 0).astype(np.uint8)
# Fold the data (ex: 352 x 352 x 3 folded into 88 x 88 x 48) if required and save to pt file
if self.fold_ratio == 1:
img_crp_folded = img_crp
else:
img_crp_folded = None
for i in range(self.fold_ratio):
for j in range(self.fold_ratio):
if img_crp_folded is not None:
img_crp_folded = np.concatenate((img_crp_folded, img_crp[i::self.fold_ratio, j::self.fold_ratio, :]), axis=2)
else:
img_crp_folded = img_crp[i::self.fold_ratio, j::self.fold_ratio, :]
pickle.dump((img_crp_folded, img_crp_lbl), open(pickle_file, 'wb'))
Data Loader Method and Transformer Definitions
The data loader method/s are the second required component customized data loader module. For the sample AISegment dataset, two different data loader functions are implemented. The first one (AISegment_get_datasets) returns images of size 80x80 using a smaller U-Net network model. The latter one (AISegment352_get_datasets) returns images of size 352×352. Below is the implementation of the second one that generates AISegment objects with required properties. The compound transformers are also defined within this function. Also, if truncation is required, the test dataset is truncated.
def AISegment352_get_datasets(data, load_train=True, load_test=True):
"""…"""
(data_dir, args) = data
if load_train:
train_transform = transforms.Compose([
transforms.ToTensor(),
ai8x.normalize(args=args)
])
train_dataset = AISegment(root_dir=data_dir, d_type='train',
transform=train_transform,
im_size=[352, 352])
else:
train_dataset = None
if load_test:
test_transform = transforms.Compose([
transforms.ToTensor(),
ai8x.normalize(args=args)
])
test_dataset = AISegment(root_dir=data_dir, d_type='test',
transform=test_transform,
im_size=[352, 352])
if args.truncate_testset:
test_dataset.data = test_dataset.data[:1]
else:
test_dataset = None
return train_dataset, test_dataset
Dataset Dictionary
The dataset dictionary is the third required component of the customized data loader module that includes available data loader functions. For the sample AISegment data loader, as there are two variants of datasets that generate dataset entities with different resolutions (80×80 or 352×352), the dataset dictionary has two entities, each including the proper definition of input and output sizes and data loader function names.
Testing Trained Model with Images
After the model development phase, one can test the model using test datasets or arbitrary samples. The critical point is that proper transformation/s data loader implements must be done externally before providing input to the model.
For example, the sample model trained with AISegment datasets expects the input of shape [48, 88, 88], which is a channel first representation of folded RGB images of resolution 352×352 with normalized pixel values as needed for the MAX7800X. The externally provided test image may not even have the same color format, but the required transformation must be implemented beforehand as the model is trained for RGB images. Below is an example code snippet for a testing model with a portrait image with 470×470 resolution and YbCr color format:
rgb_img = yuv_img.convert('RGB')
rgb_img_ds = rgb_img.resize([352, 352])
# Image to numpy array conversion:
rgb_img_ds = np.asarray(rgb_img_ds).astype(np.uint8)
# Fold image (352 x 352 x 3 folded into 88 x 88 x 48)
rgb_img_ds_folded = fold_image(rgb_img_ds, 4)
# Covert pixel values to range [0 1] and cast to float type (required for Torch)
rgb_img_ds_folded_scaled = (rgb_img_ds_folded / 256).astype(np.float32)
# Normalize for MAX78000
# Set act_mode_8bit=True as we will set model parameter simulate=True
args = Args(act_mode_8bit=True)
transform = transforms.Compose([
transforms.ToTensor(),
ai8x.normalize(args=args)
])
rgb_img_ds_folded_scaled_normalized = transform(rgb_img_ds_folded_scaled)
# Add batch dimension
rgb_img_batch = rgb_img_ds_folded_scaled_normalized.unsqueeze(0)
# Load model
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
load_model_path = 'unet/qat_ai85unet_v7_352_4_best_q.pth.tar'
ai8x.set_device(device=85, simulate=True, round_avg=False)
model = mod.AI85Unet_v7_pt(num_classes=2, num_channels=3, dimensions=(88, 88),
bias=True, fold_ratio=4)
checkpoint = torch.load(load_model_path, map_location=lambda storage, loc: storage)
ai8x.fuse_bn_layers(model)
model = apputils.load_lean_checkpoint(model, load_model_path, model_device=device)
ai8x.update_model(model)
model = model.to(device)
# Run model
with torch.no_grad():
sample_img_rgb_batch = rgb_img_batch.to(device)
model_out_rgb = model(sample_img_rgb_batch)
# Retrieve model output
out_vals = np.argmax(model_out_rgb[0, :, :, :].detach().cpu().numpy(), axis=0)
plt.imshow(out_vals, cmap='Greys')
Figure 5 includes a sample external test data item given in YCbCr format, the corresponding RGB image, and the model output after all required transformations are performed. First, color space needs to be converted to RGB. Then images should be downsampled to have a 352 × 352 resolution. The next operation is folding, requiring transformations, and normalization.

Figure 5. Sample portrait image in YCbCr Color Space, RGB space, and the model output.
参考电路
1 Writing Cystom Datasets, Dataloaders and Transforms.
2 https://github.com/MaximIntegratedAI/ai8x-training, refer to the README for instructions.
3 AISegment.com - Matting Human Datasets