A 12-b 10-GS/s Interleaved Pipeline ADC in 28-nm CMOS Technology
Abstract
A 12-bit 10-GS/s interleaved (IL) pipeline analog to-digital converter (ADC) is described in this paper. The ADC achieves a signal to noise and distortion ratio (SNDR) of 55 dB and a spurious free dynamic range (SFDR) of 66 dB with a 4-GHz input signal, is fabricated in the 28-nm CMOS technology, and dissipates 2.9 W. Eight pipeline sub-ADCs are interleaved to achieve 10-GS/s sample rate, and mismatches between sub-ADCs are calibrated in the background. The pipeline sub-ADCs employ a variety of techniques to lower power, like avoiding a dedicated sample-and-hold amplifier (SHA-less), residue scaling, flash background calibration, dithering and inter-stage gain error background calibration. A push–pull input buffer optimized for high-frequency linearity drives the interleaved sub-ADCs to enable >7-GHz bandwidth. A fast turn-ON bootstrapped switch enables 100-ps sampling. The ADC also includes the ability to randomize the sub-ADC selection pattern to further reduce residual interleaving spurs.
Index Terms—Calibration, CMOS, digitally assisted analog design, direct RF sampling analog-to-digital converter (ADC), gigahertz data conversion, interleaved (IL) ADC, pipeline ADC, switched capacitor.
Introduction
Recent progress in high-speed analog-to-digital converter (ADC) design with resolution greater than 10 b and sample rates well into the gigahertz range have made software-defined radios practical for a variety of applications, including communication systems and data acquisition systems [1]–[5]. While narrower band radios, as in the heterodyne receiver shown on the upper half of Fig. 1, have traditionally been used, developments in data conversion technology have enabled a wideband ADC to replace a significant part of the signal chain as shown in the lower half of Fig. 1, thereby lowering system complexity, power, and cost.

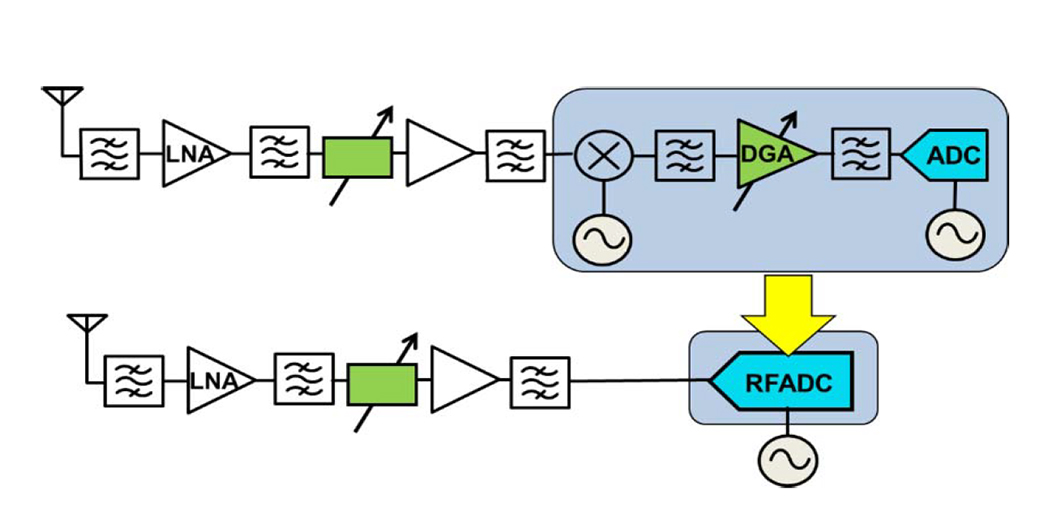
Fig. 1. Traditional heterodyne receiver versus direct RF receiver.
Wireless infrastructure systems such as macro cellular base stations, satellite communication systems, as well as electronic warfare systems and high-performance bench measurement systems, are driving the demand for directly digitizing signals with gigahertz-wide bands (sometimes resulting from merging multiple separate sub-bands, co-existing at different carrier frequencies) located up at RF frequencies as high as 3.2 GHz, and with fairly high linearity (e.g., SFDR of the order of 70 dB at 1 GHz or higher) and low-noise spectral density (e.g., noise spectral density (NSD) of the order of –150 dBFS/Hz or better). Unfortunately, as the sample rate (fs) of an ADC is increased, its power consumption increases: first linearly with fs then super-linearly with fs; thereby, making the ADC increasingly inefficient and eventually making its implementation impractical. Interleaved (IL) ADCs can enable higher sample rate conversion while keeping power consumption manageable. However, multiple design trade-offs are involved and many architectural and circuit design challenges need to be overcome.
In this paper, a 12-b 10-GS/s IL pipeline ADC that is fabricated in 28-nm CMOS technology is described [6]. The ADC interleaves an array of eight 12-b pipeline sub-ADCs that are driven by a single input buffer, and employs a variety of calibration, dithering, and randomization techniques to improve spectral performance.

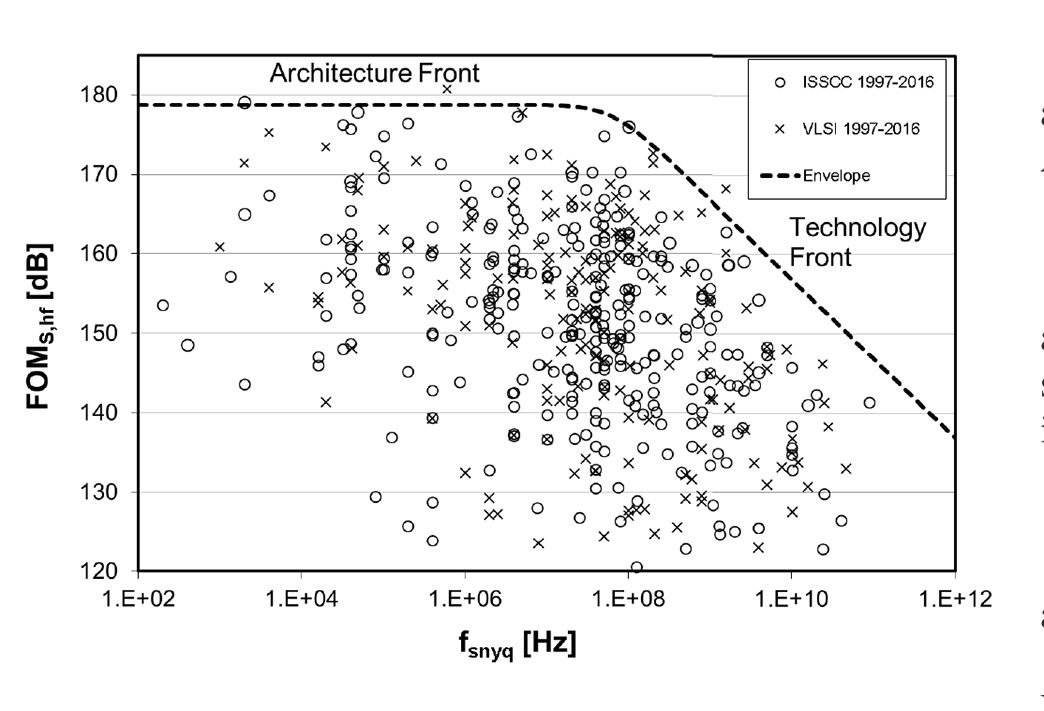
Fig. 2. Schreier FOM and associated ADC trends [8].
This paper is organized as follows. In Section II, some of the architectural trade-offs and challenges associated with interleaving at gigahertz sample rates are outlined. Section III begins with a description of the overall architecture employed in this design and the various interleaving calibrations. Next, in Section III-A the architecture and circuits associated with the sub-ADCs, along with their calibration and dithering are discussed. Section III-B covers the front-end circuit design including the input buffer, and Section III-C discusses the residual effects of sequentially interleaving the sub-ADCs, and the bene.ts of randomizing sub-ADC selection. The measurement results from a prototype IC are reported in Section IV. A comparison with similar state-of-the-art ADCs is the topic of Section V. Finally, summary and conclusions are provided in Section VI.
Interleaving and Architectural Tradeoffs
A commonly used figure-of-merit (FOM) to assess the power efficiency of an ADC, known as the Schreier FOM, is
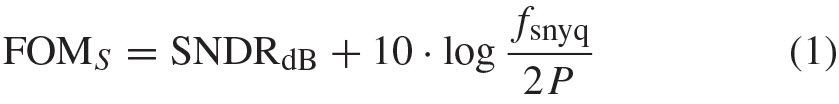
where SNDRdB is the signal-to-noise and distortion ratio expressed in decibel, fSNYQ is the Nyquist sample rate (corresponding to the sample rate fs divided by the oversampling ratio) and P is the power consumption [7]. A scatter plot showing this FOM [8], depicted in Fig. 2, shows how the highest sample rate ADCs rapidly decline in efficiency, lie within the asymptotic diagonal dashed line commonly known as the “technology front”, and are mainly limited by the transistors’ speed in a given process technology. So, as newer ADCs adopt finer lithography CMOS processes with faster devices, the technology front shifts toward the right [7] and higher sample rate ADCs become practical.
While this is true for non-IL (or single core) ADC architectures, IL (or parallel) ADCs offer the theoretical potential to extend the limit imposed by the process technology’s speed [9]. In fact, at least in principle, by interleaving M identical ADCs (called sub-ADCs), each one clocked at fsc and consuming Pc watts, an IL ADC sampling at fs = M · fsc and consuming P = M · Pc watts could be designed.
At first, one could conclude that an IL ADC should be just as power efficient as its sub-ADCs, since the FOM for the IL ADC is
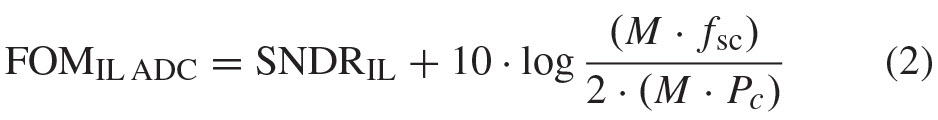
and since, in principle, the SNDRC of the sub-ADCs is the same as the SNDRIL of the IL ADC, then by substitution in (2)
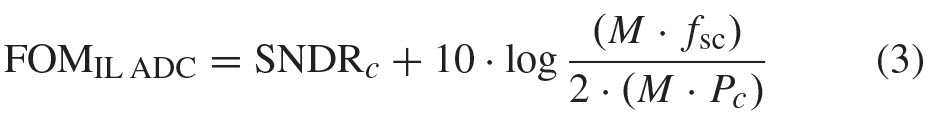
and finally
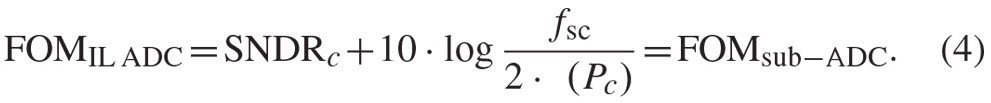
Therefore, referring back to Fig. 2, starting a design from a sub-ADC with FOMsub-ADC, located on the left of the technology front, and interleaving with increasing M, one could conceive to build faster and faster IL ADCs, with constant FOM (adding new points to the graph for greater fs but with constant abscissa), eventually crossing over the limit set by the technology front.
In practice, however, to build the IL ADC out of the sub-ADCs, quite a bit of additional circuit overhead is necessary. This includes signal buffering, routing, references, clocking and controls, the front-end interface to the input signal source, the digital back-end de-multiplexing, the power supplies for the different sections, and calibration circuitry. All this consumes additional power Po, which grows linearly or super-linearly with both M and fs, and hence, when introduced in the denominator of the argument of the logarithm of (2), reduces the actual efficiency of the IL ADC
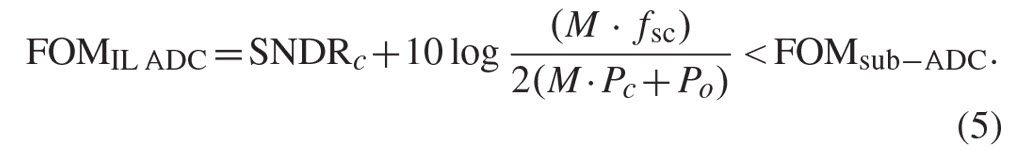
Since the highest FOMs are obtained in non-IL ADC architectures with lower sample rate, such as successive approximation (SAR) converters, it is becoming common for lowering power dissipation to find such SAR sub-ADCs in IL ADCs implemented with large interleaving order M [9]-[14]. However, the above model, as well as other much more complex analytical representations [15], [16] do not capture other important architectural considerations that impact the resulting IL ADC’s spectral performance and driveability.
While very power efficient, high interleaving order ADCs (say, M > 10) suffer from a number of practical implementation challenges that limit their resolution to about 10 b [17], [18]. Moreover, as M increases, the input buffer must drive more sub-ADCs, thereby increasing front-end loading, which degrades input bandwidth (BW) and linearity, and increases power consumption [16], [17]. Conversely, higher sample rate sub-ADC architectures, such as pipelined sub-ADCs [19], while slightly less power efficient, reduce M (for the same fs), which helps decrease front-end loading, reduce implementation challenges, complexity and overhead, and have demonstrated higher resolution [20]-[22].

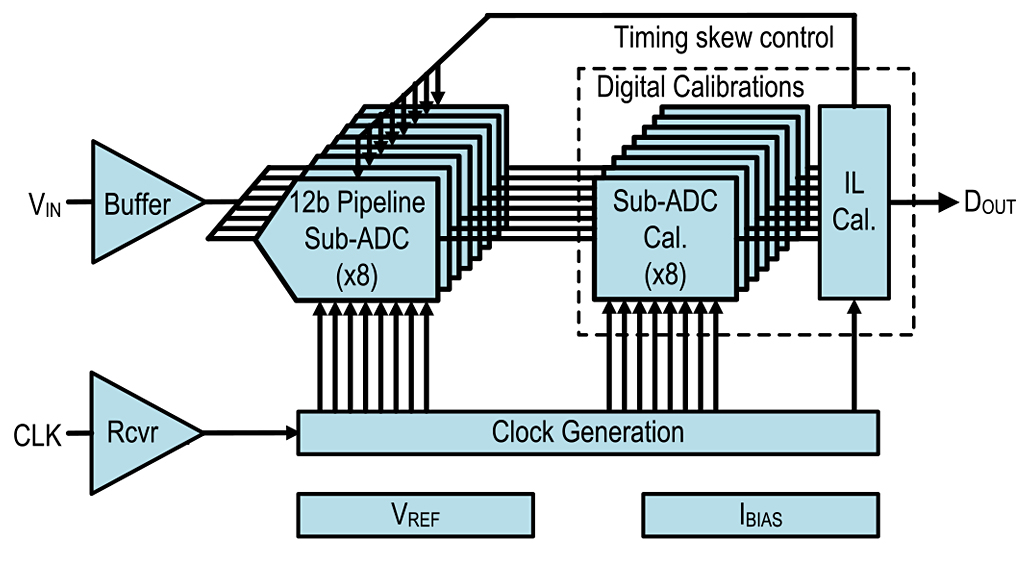
Fig. 3. 12-b 10-GS/s ADC architecture.
So, while both higher M SAR arrays and lower M pipelined arrays have merits, based on the stringent spectral performance and wide BW targets, a pipeline sub-ADC architecture is chosen for this work, and various techniques are employed to lower the power dissipation of the pipeline sub-ADCs. A recently published 14 b 2.5-GS/s pipeline ADC [5] is the fastest non-IL pipeline ADC at these performance levels, and serves as an important data point on the speed limit for such pipeline ADCs in 28-nm CMOS. Our assessment indicated that in the 28-nm CMOS technology power efficient pipeline sub-ADCs can be designed for sample rates below 2 GS/s. Further, using a binary number of sub-ADCs in an IL ADC allows in general better matching layout. Considering all of this, eight sub-ADCs are interleaved in this work to achieve 10 GS/s, and this architecture choice has similarities to other IL pipeline ADCs [20], [18].
Interleaved ADC Architecture
The overall ADC architecture is shown in Fig. 3. Eight pipeline sub-ADCs are interleaved to achieve the 10-GS/s sample rate. A single common input buffer is used to drive the input signal, VIN, to all the eight sub-ADCs. The digital outputs of the eight sub-ADCs go to individual sub-ADC digital calibration blocks that correct for sub-ADC imperfections. The individually corrected sub-ADC outputs go to a common IL calibration block, which estimates and corrects mismatches between the sub-ADCs that would otherwise cause mismatch tones [15], [16]. Both the estimation and correction aspects of all calibrations are implemented on-chip. Offset, gain, and timing mismatches are calibrated in the background to ensure good spectral performance. Offset and gain mismatches are both estimated and corrected in the digital domain [23]. However, for timing mismatches the estimation is done digitally but the correction is done in the analog domain [16], [24], [12]. To estimate the timing skew, it is assumed that IL offset and gain are already calibrated. If all sub-ADCs sampled at equally spaced instants in time, then they will all have the same correlation to neighboring sub-ADC samples on average. If a sub-ADC is skewed early, then it will be more correlated with the samples immediately before it, and less correlated with the samples immediately after it, again, on average [16]. For each sub-ADC, a correlation is performed between its output and the sample immediately after it. If ADC[n]sub-ADC_M is the nth overall ADC sample taken with the Mth sub-ADC, then the correlation value of interest is
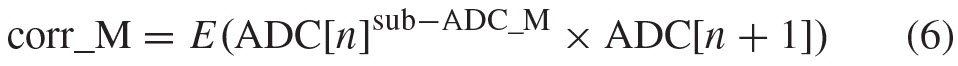
where E is the expected value or mean. One of the sub-ADCs is taken as a reference, and all other sub-ADC timing skews are periodically adjusted based on their difference from this reference correlation using a recursive digital feedback loop that operates on an average of samples continuously in the background [16]. The correction of the timing mismatch could be done digitally with finite-impulse response filters [22], but even in an advanced process like 28-nm CMOS the power dissipation of such a filter with 10 fs timing resolution would be substantially higher than analog skew correction, which is accomplished by loading the sample clock driver with a capacitive digital to analog converter (DAC) [22]. The complete timing-skew digital feedback loop and the DAC it controls within each sub-ADC are shown in Fig. 4. The sample time is adjusted by turning on (or off) a switch to load (or unload) the inverter to delay (or advance) the sampling clock.
To complete the architecture description, as shown in Fig. 3, a differential clock receiver (Rcvr) is driven from an off-chip 10-GHz clock (CLK) generator, and the output of the clock receiver goes to clock generation circuitry that generates all interleaving clock phases to control the sub-ADC operations such as sampling, coarse quantization in the flash, and multiplying DAC (MDAC) residue generation. The ADC includes on-chip reference voltage generation and bias current generation circuitry.
A. Sub-ADC Architecture and Circuit Implementation
As discussed earlier in Section I, this work interleaves relatively fast (>1.25 GS/s) pipeline sub-ADCs. The pipeline architecture in advanced CMOS technologies like 28 nm enables such GHz sub-ADCs with very good spectral performance. In this work, several techniques are employed to minimize the power consumption of the pipeline sub-ADCs without sacrificing performance. In order to minimize power consumption, the pipeline sub-ADC is designed to operate from the core 1-V supply. One of the key challenges with a low-voltage pipeline is the design of an MDAC amplifier with sufficient swing, gain accuracy, and linearity [25]. The pipeline sub-ADCs are designed to handle an input signal swing of 1.4 Vpp-differential, which creates challenges to designing an MDAC on a 1-V supply. Using a higher supply for the MDAC amplifier would result in higher power and complexity, which includes additional circuitry for voltage stress mitigation when low-voltage MDAC amplifier transistors are used with a higher-than-rated supply, and increased supply routing complexity due to multiple supply voltages. Further, with multiple supply domains in a switched-capacitor MDAC circuit, the clocks and boosters may need further level shifting (LS). All of this would translate into a larger area for the sub-ADC design, which in turn increases overall IL ADC power consumption in terms of clocking parasitics and the parasitics that the input buffer has to drive. In this work, the MDAC amplifier is designed to operate from the 1-V supply to minimize area and power, and a combination of analog circuit techniques and digital calibration techniques are used to ensure good performance.

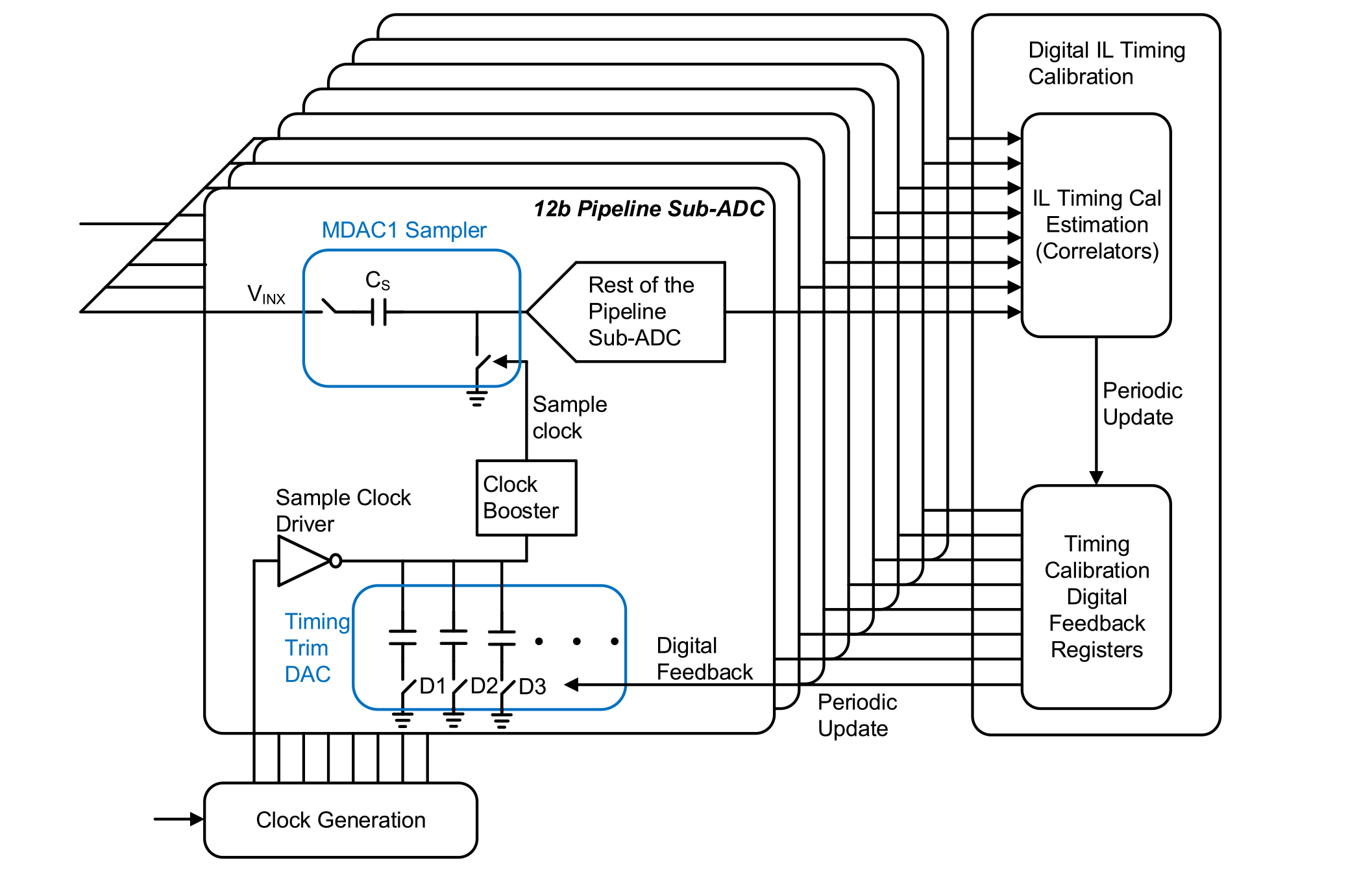
Fig. 4. Timing-skew correction DAC and entire digital feedback that controls this DAC.

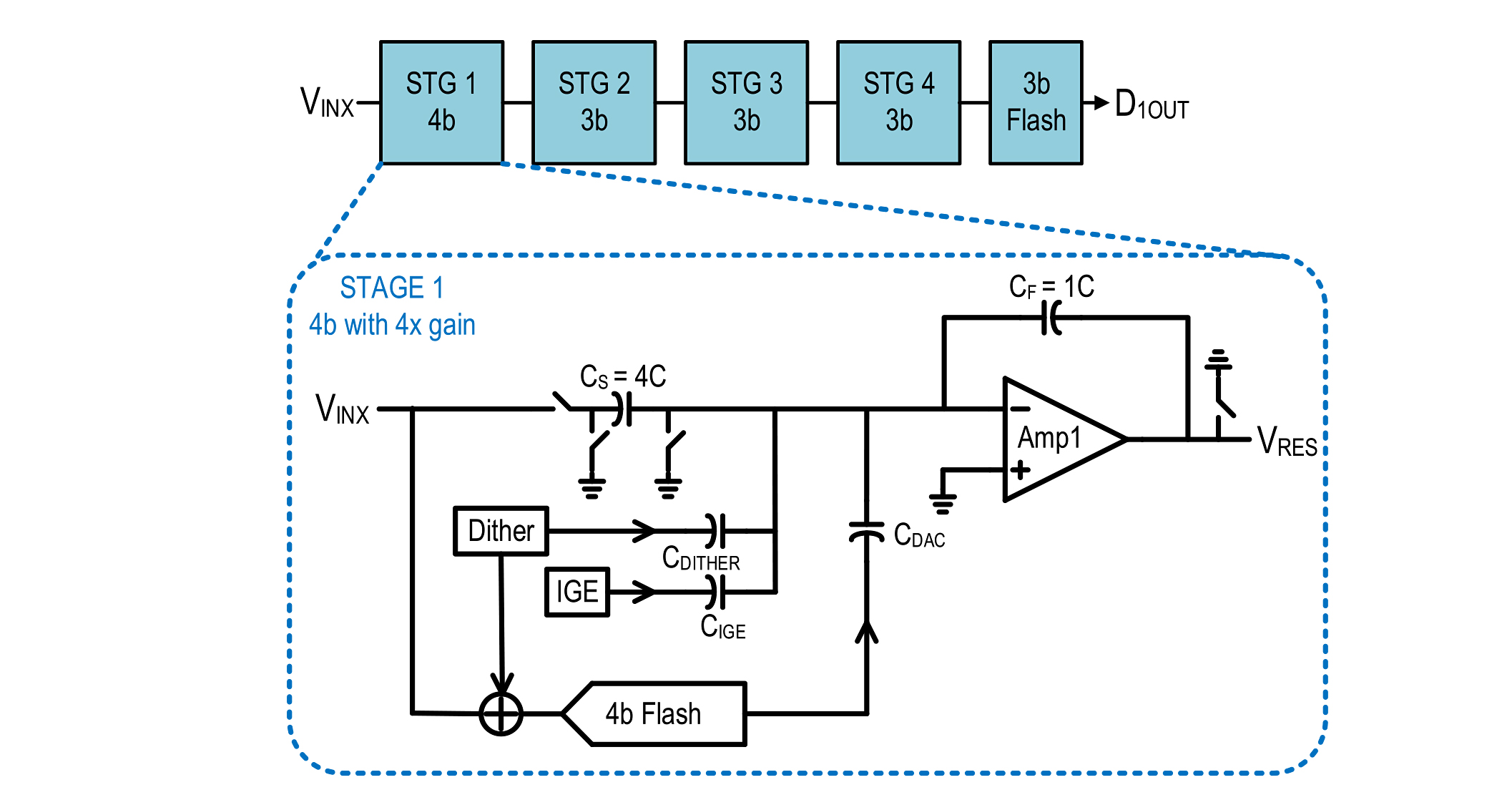
Fig. 5. 12-b pipeline sub-ADC architecture and stage1 implementation details.
The architecture of the pipeline sub-ADC is shown in Fig. 5. The pipeline consists of a 4-b first stage, followed by three 3-b stages and a final 3-b flash. The choice of MDAC resolution (bits per stage) between 2 and 4 b is generally considered a reasonably shallow optimum in thermal noise limited designs [26]-[28]. The pipeline sub-ADC is SHA-less, which avoids the power, noise, and distortion overhead of the SHA, but introduces stringent matching requirements in terms of track BW between the MDAC and the flash [29].
The implementation details of the first stage of the pipeline sub-ADC, stage1, are also shown in Fig. 5. The input signal VINX is sampled on the sampling capacitor CS, and a 4-b flash coarsely quantizes VINX simultaneously. The output of the 4-b flash drives a DAC capacitor CDAC, and CDAC subtracts charge from CS. The use of a separate DAC capacitor as opposed to reusing CS to also do the DAC function has well known trade-offs [30], [28]. The benefits of a separate CDAC are: 1) the charge glitch on the reference buffer is signal independent, which allows the use of a low-power reference buffer and 2) CS does not have non-linear quantization charge on it at the end of the hold phase, which removes the need for an explicit reset phase before CS goes back to track, thereby saving power.
The disadvantages of a separate CDAC are increased noise and lower feedback factor. The MDAC amplifier, Amp1, generates the residue, VRES, to the next stage. Dither is injected in stage1 to linearize the sub-ADC transfer function [28], and inter-stage gain error (IGE) calibration is also performed to correct MDAC gain errors in the background [31]. The reference buffer, which is not explicitly shown in Fig. 5, is implemented as a complementary push–pull source follower to ensure fast settling of the CDAC capacitor when the MDAC is in hold phase. Each MDAC stage within each sub-ADC has its own reference buffer and the mismatches between the reference buffers are corrected as part of the background digital calibrations. Using a common reference buffer for all MDACs would have resulted in that buffer having to drive the routing parasitic capacitance to each MDAC, thereby resulting in a higher power dissipation.
The comparators in the 4-b flash use small devices for low power and small area, so their process mismatches consume significant correction range. To overcome this, the 4-b flash employs a background calibration scheme to correct comparator offsets as shown in Fig. 6. The 4-b flash in this work normally requires 16 comparators (the MDAC transfer function with the 16 comparators transitions is explained later in this section [28]) however, an extra 17th comparator is added for this background calibration scheme. At any given time, only 16 comparators are needed for the main signal path operation, so one of the 17 comparators is removed offline and calibrated in the background. All the comparators are rotated around sequentially to ensure all their offsets are periodically calibrated. In Fig. 6, the comparator being calibrated is highlighted.

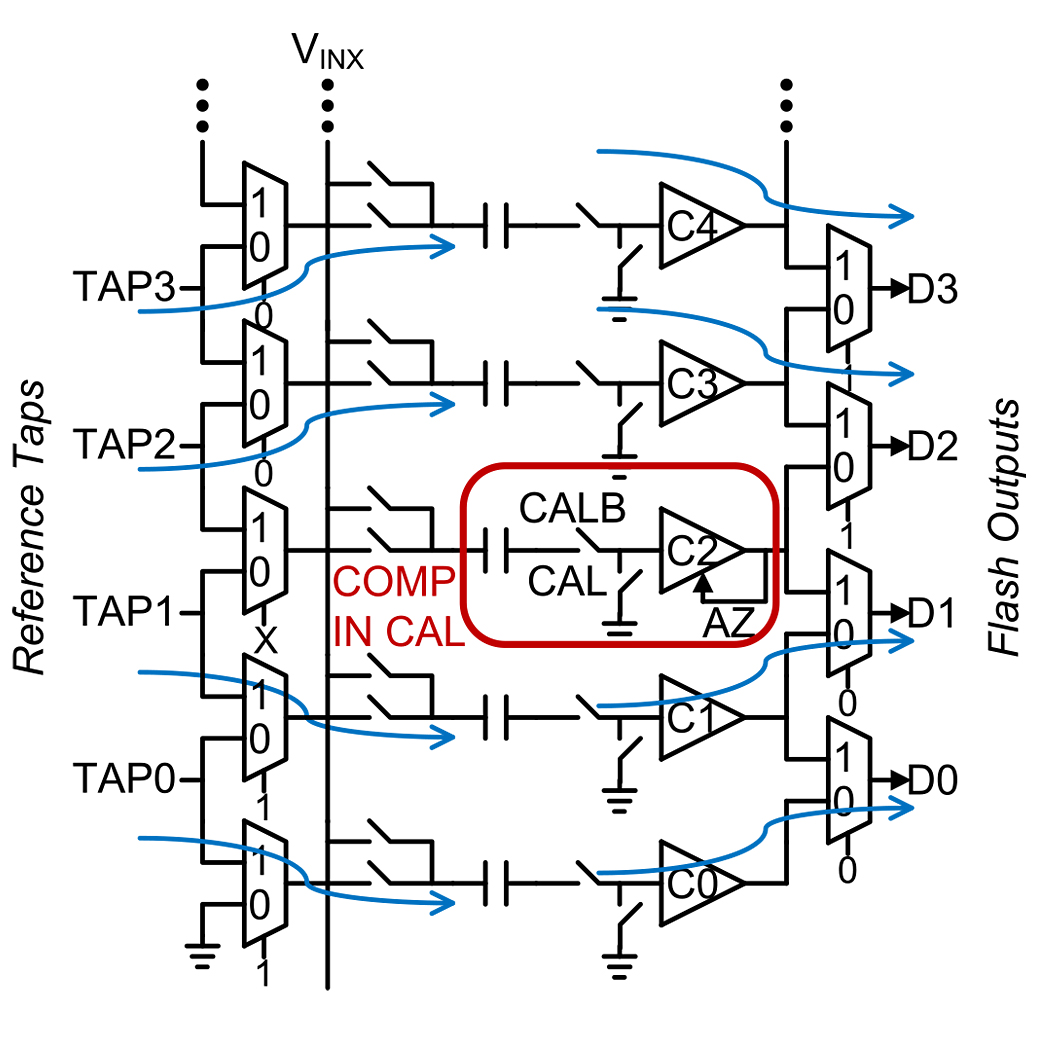
Fig. 6. Flash1 background comparator offset calibration.
The reference taps and the output data bits from the comparators are multiplexed as shown around the comparator in calibration to ensure the signal path functionality is not affected by removing a comparator offline for calibration. The comparator that is being auto-zeroed has its inputs disconnected from the sampling network and shorted to provide a zero input. The background offset calibration not only removes offsets over process, supply, and temperature variations but also offset drift with transistor aging, which can be severe in advanced CMOS technology like 28 nm.

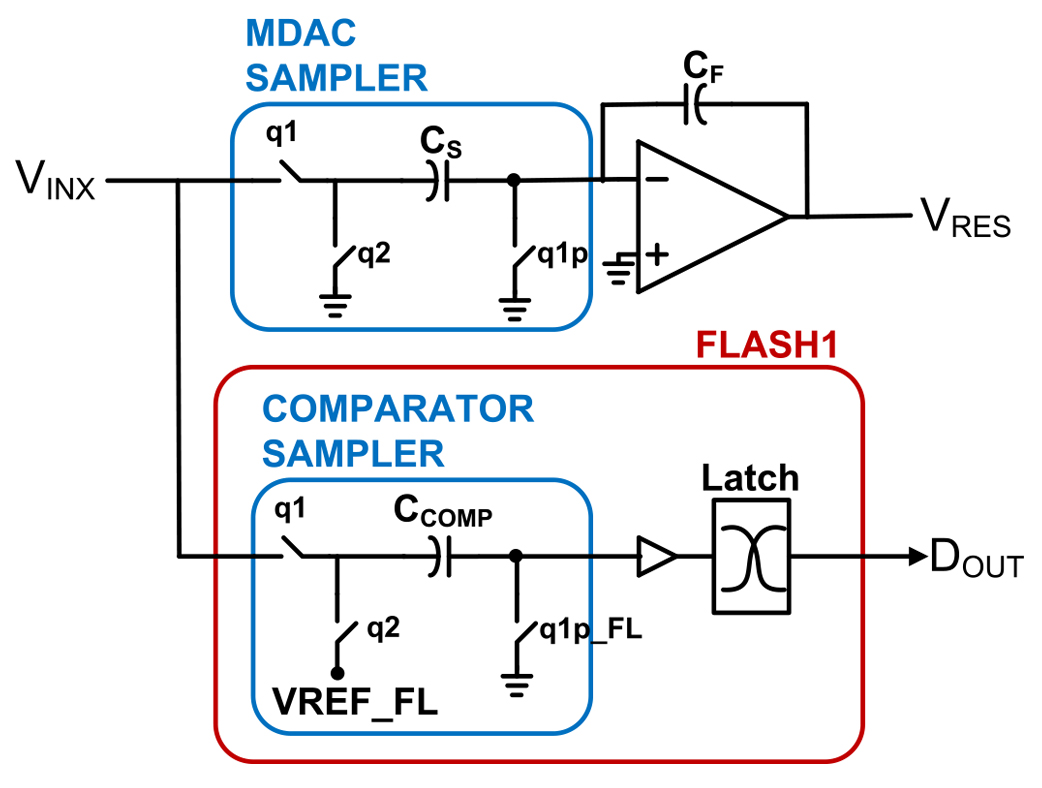
Fig. 7. Flash1 sampling comparator architecture to ensure BW matching between flash1 and MDAC1.
An important SHA-less consideration is that, since both the flash and the MDAC in stage 1 sample GHz inputs, small BW mismatches can consume significant correction range. To minimize BW mismatches a sampling comparator architecture [29] is used in flash1 as shown in Fig. 7. VINX is passively sampled in both the MDAC and the flash first, and then the latch fires to generate the output from the comparator. While this sequential operation adds delay in the comparator as opposed to directly sampling at the latch, the benefit is the ability to very closely match the track BWs of the MDAC and the flash since they are both distributed RC networks when tracking the input signal. Further, to be able to correct any BW mismatches that do exist between the MDAC and the flash, the sample clocks of the MDAC (q1p) and flash (q1p_FL) are split and a delay line is inserted in the flash sample clock path to allow trimming of the flash sample time. This trim is done in the foreground by monitoring the residue of stage1 VRES and minimizing its amplitude under high-frequency input signal conditions by trimming the flash sample clock delay.

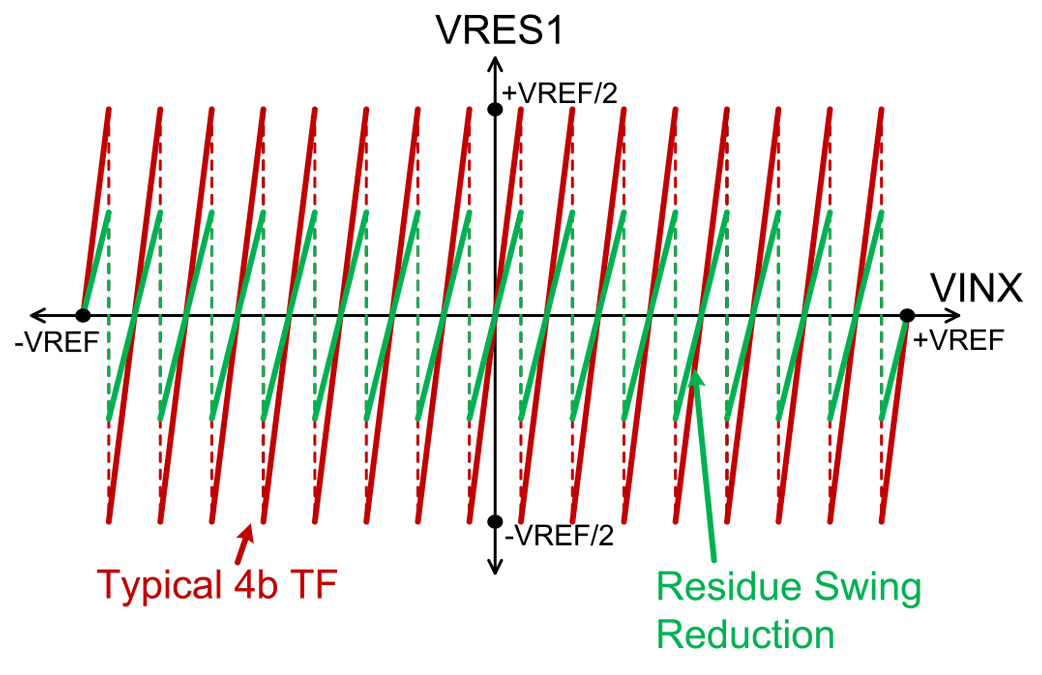
Fig. 8. Stage1 residue transfer function.
In a 4-b stage, the gain of the MDAC is typically set to 2(4-1) = 8. However, to enable the stage1 MDAC to operate off the core supply the residue gain is reduced to 4 in this work, as shown in Fig. 5 with the ratio of CS/CF = 4. Fig. 8 compares the two stage1 transfer functions (TF) of a typical 4-b stage with a gain of 8 with the implemented 4-b stage with a gain of 4. While this residue gain reduction halves the swing at the output of Amp1 and improves linearity, it doubles the backend (i.e., stages 2 to 5) noise referred to input. However, the power increase in the back-end stages to reduce their noise contribution was smaller than the power savings obtained in the stage1 MDAC by halving its swing. Fig. 8 also shows the locations of the 16 comparator flash transitions in the 4-b MDAC.
The MDAC amplifier’s simplified transistor-level implementation is shown in Fig. 9. The amplifier is a two-stage design with a split Cascode compensation scheme. Both stages use a push–pull complementary architecture to double the power efficiency (i.e., double gm/I). However, the push–pull architecture requires different bias points for the PMOS and the NMOS, which is implemented by using dynamically level-shifted capacitors (CLS1 and CLS2). Each level-shifted capacitor is charged to the desired level-shift voltage using a switched-capacitor circuit that operates on non-overlapping complementary clocks q1 and q2 [32]. As shown in Fig. 9, a small capacitor CSMALL is charged to the desired level-shift bias voltages (VBIASP and VBIASN), and this small capacitor is periodically switched in parallel with the level-shift capacitor to refresh its charge and thereby establish the level-shift voltage. The first stage of the MDAC amplifier is actively cascoded, and both stages use independent common-mode feedback circuits for better common-mode settling and stability. The amplifier is designed for fast linear settling and optimized for low power, which is made possible by taking advantage of the reduced swing, dithering, and IGE calibration techniques.
Dither is added to both the MDAC (using the CDITHER capacitor shown in Fig. 5) and the flash [28]. The dither added to the flash linearizes both residual IGE errors and nonlinearities in the stage1 MDAC residue. The dither added to the MDAC propagates down the pipeline and linearizes differential non-linearity (DNL) errors in the back-end ADC. Only mismatches between the MDAC dither and the flash dither end up using correction range, and these mismatches are small relative to the correction range. A random 1-bit generator (labeled IGE in Fig. 5) drives a capacitor CIGE to inject charge into the MDAC that is used to digitally estimate the IGEs in the MDAC [31]. Once estimated, the IGE is then digitally corrected in the background.
B. Front End
The front end of the eight-way IL ADC is shown in Fig. 10. A common input buffer is shown driving the sampling networks within each of the eight sub-ADCs. This isolates the input VIN from the loading of the eight sub-ADCs, which improves BW and linearity. To minimize loading on the input buffer and crosstalk between sub-ADCs, only one of the eight sub-ADCs is connected to and tracking the output of the buffer at any time. That is, only one of the eight VBTSTRP [1:8] is turned on at any time. The seven off input switches present a significant non-linear parasitic on the input buffer that degrades high-frequency linearity, and to reduce this impact, the back gates of these input switches are biased to a –1 V voltage to reduce CSB non-linearity.
A trade-off exists between the choices of a single common input buffer, as used in this work, versus separate input buffers driving each of the eight sub-ADCs. The gm and power of the buffer to achieve the target BW and linearity at high-frequency inputs is determined by the capacitive loading. When the loading of the buffer is dominated by the sampling capacitor CS, and with only one sub-ADC sampling at any time, one can argue that a single common buffer is 8× lower power than eight separate buffers, since each of those separate buffers would have to burn the same power to supply the ac current needed when its sub-ADC is sampling with a loading of CS. However, in reality the common buffer is not 8× lower power, since the metal routing to the eight sub-ADCs and the seven off input switches add additional parasitic capacitance. However, as long as these two additional parasitic capacitances are significantly smaller than 7 × CS, using a common buffer can be a significant net power saving. Further, with separate input buffers the total capacitance presented to VIN would also increase, which would significantly lower BW. Based on BW, power, and linearity considerations, a single common buffer is used in this work.

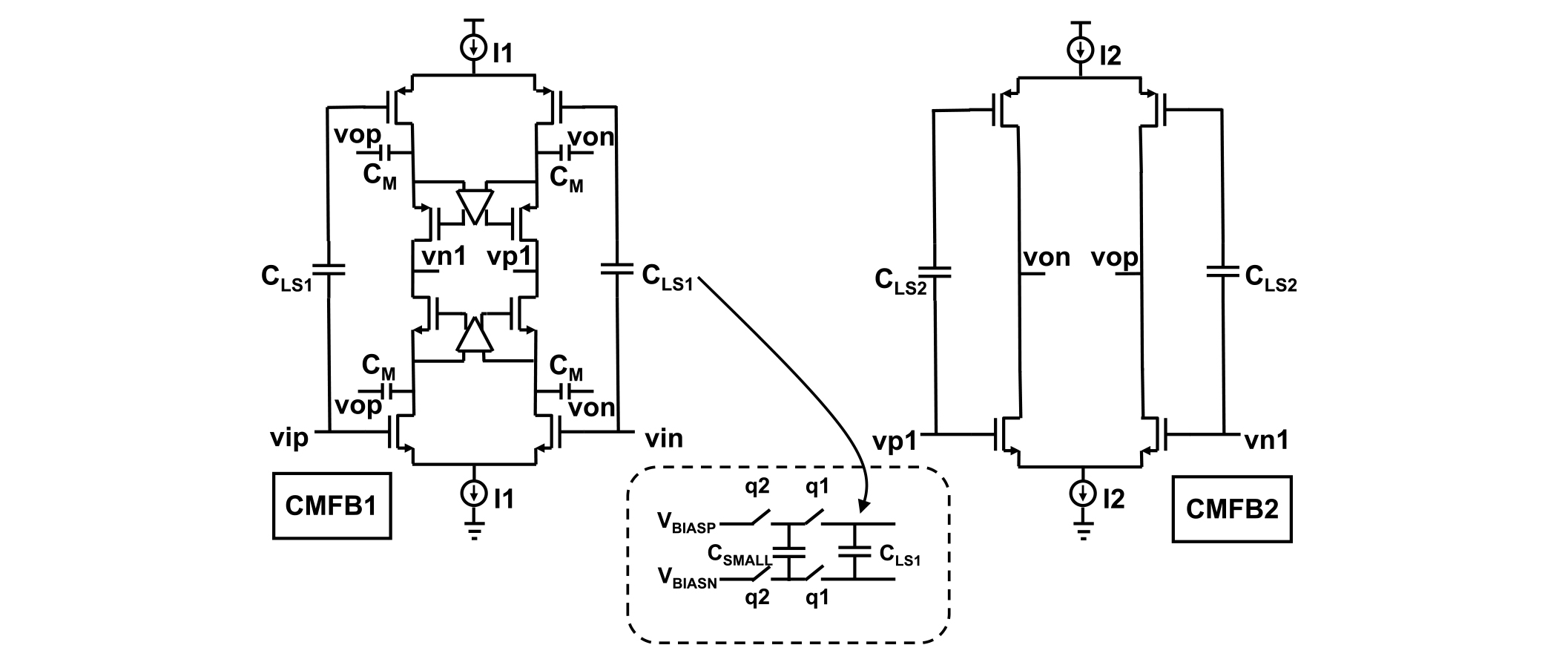
Fig. 9. MDAC1 amplifier transistor level implementation details.
The input buffer implementation details are shown in Fig. 11. A pseudo-differential complementary push–pull architecture is used, which doubles gm/I. However, a push–pull design requires different bias points for the NMOS and PMOS devices, which are implemented with a level shifting (LS) circuit comprised of a current source developing a bias voltage across a high valued resistor that is bypassed with a large feed-forward capacitor. Two levels of cascodes are bootstrapped to the input VIN to reduce drain modulation of the input devices of the buffer, which improves linearity, but necessitates the use of higher supply voltages for the buffer.

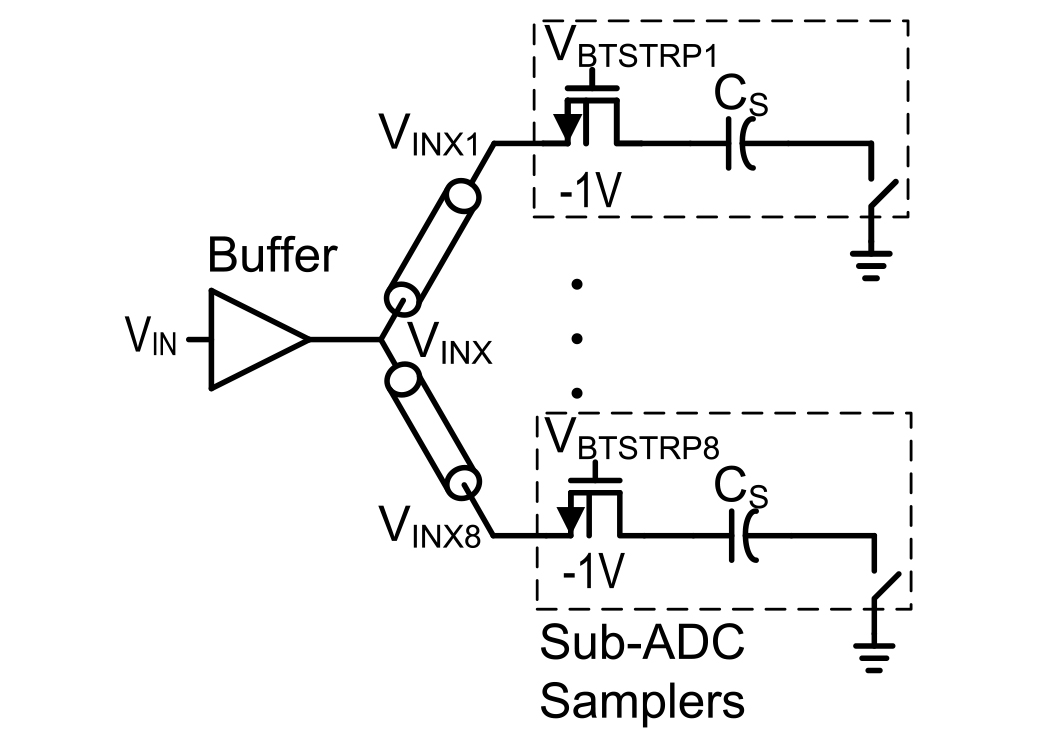
Fig. 10. Front-end circuitry showing the input buffer driving the eight sub-ADC samplers.
The input buffer is powered by 2 and –1 V supply rails, and each of the transistors is biased to ensure they are in saturation with about >150 mV VDS – VDSAT margin. While the input devices and the inner cascodes are driven directly from the input VIN through LS circuits, the outer cascodes are driven from the sources of the inner cascodes. The two other choices to drive the outer cascode gates are either the input VIN or the output of the buffer VINX. Both of those choices degrade buffer linearity since the drains of the outer cascodes are not bootstrapped to the input, resulting in a large non-linear gate current at high input frequencies. The backgates of the various transistors in the buffer are bootstrapped, as shown in Fig. 11 to further improve buffer linearity. While the innermost input devices have their backgates tied locally to their sources, the backgates of the cascodes are tied to the equivalent small-signal points on the complementary side of the stack, which increases reverse bias on the backgate diodes, thereby reducing non-linearity.

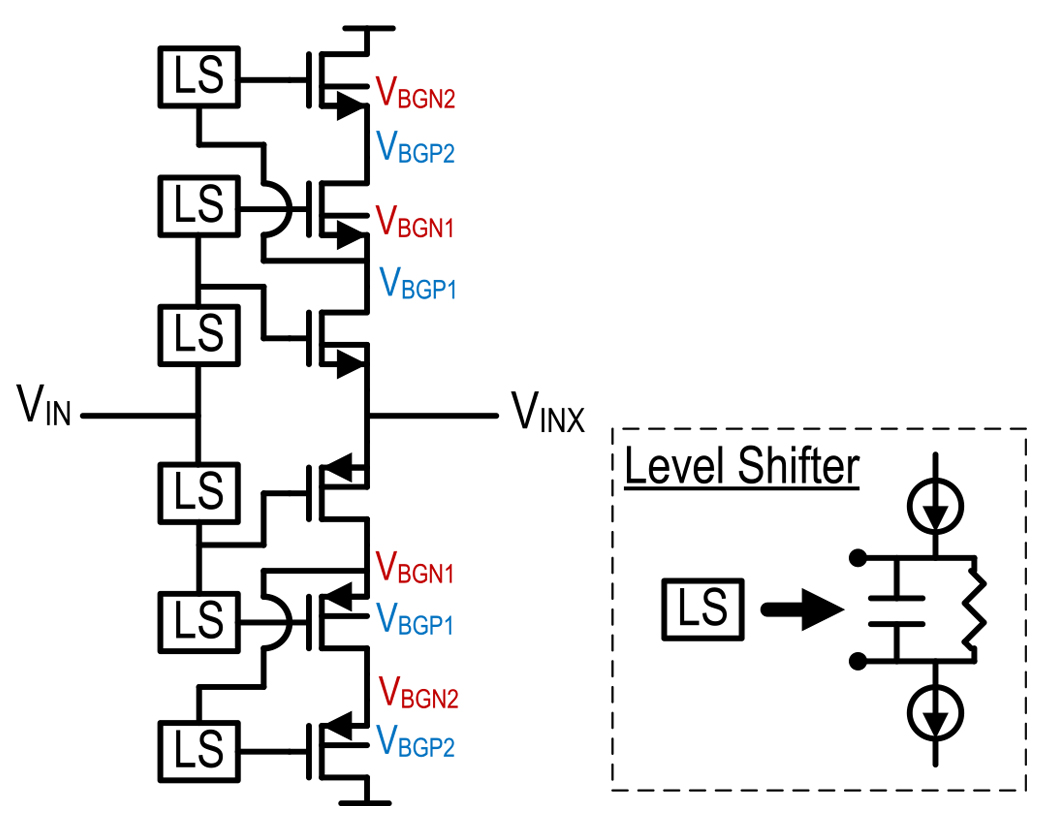
Fig. 11. Input buffer implementation details.
With each sub-ADC allocated 100 ps at 10 GS/s for tracking and sampling the output of the buffer, a fast turn-ON bootstrapped switch is essential. The traditional bootstrapped switch is shown in Fig. 12 [25]. The operation of this switch follows the sequence of steps indicated in Fig. 12 from 1 to 5. When CLKB and its boosted version CLKBBST are high, the bootstrap capacitor CBTSTRP is charged. When CLKB goes low, first V1 goes high, and then the output VBTSTRP is weakly pulled up to VDD-VTHNMOS, which weakly turns on MN2 and MN1, thereby pulling down on the gate of MP0, which eventually pulls VBTSTRP high by connecting it to the charged CBTSTRP capacitor. This is a positive feedback circuit during turn ON, and so once VBTSTRP is high enough, MN1 and MN2 strongly pull down on the gate of MP0 until the entire circuit reaches bootstrapped steady-state operation. Note that the turn-ON speed of this bootstrapped generator could be improved if the gate of MP0 could be pulled low earlier in the sequence.

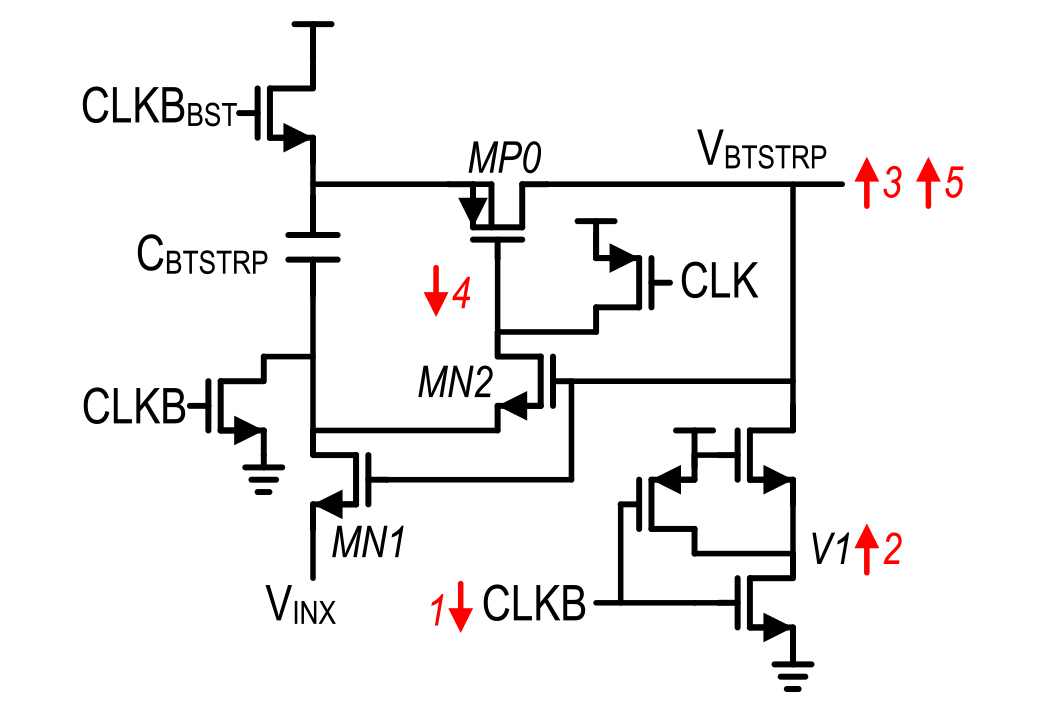
Fig. 12. Traditional bootstrapped switch gate drive generation circuitry [25].

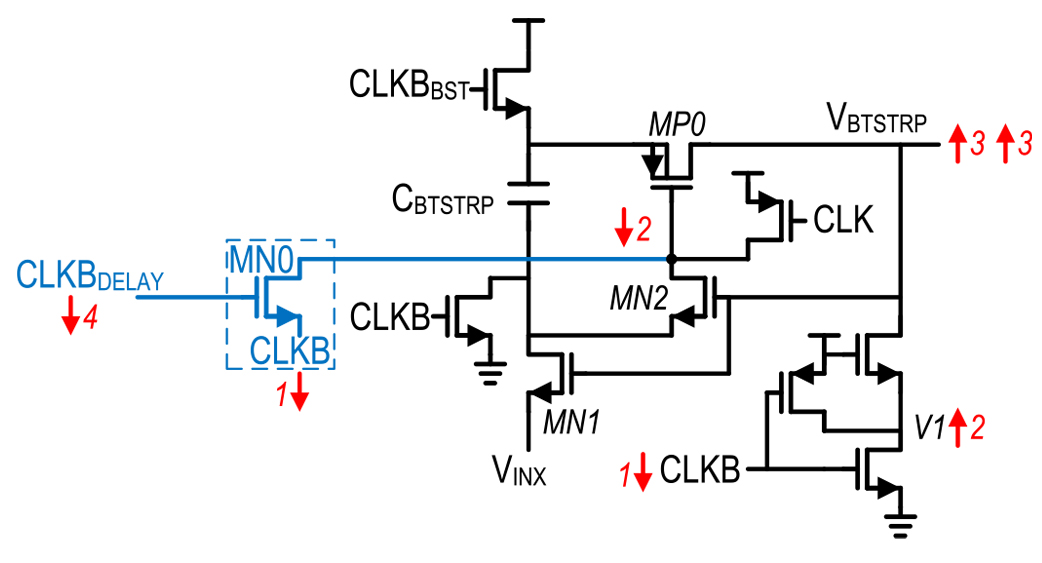
Fig. 13. Bootstrapped switch gate drive generation circuit with fast startup circuitry added.
In this work, that is achieved by adding a separate transistor MN0 to directly pull down the gate of MP0 when CLKB goes low as shown in Fig. 13. However, if MN0 remained on when MN1 and MN2 fully turn ON, it would disrupt bootstrapping operation by presenting a low impedance to the input VINX. To avoid this contention, MN0 is turned off with a delayed version of CLKB, CLKBDELAY, thereby removing MN0 from affecting bootstrapping operation once it has accelerated bootstrapped circuit turn ON.
C. Sequential and Random Interleaving
IL ADCs typically cycle through the sub-ADCs in a sequential (rotational) pattern. The eight sub-ADCs in Fig. 3 sample the input signal VIN sequentially in a rotate-by-eight sequential pattern as shown in the sub-ADC selection pattern in the top half of Fig. 14. With sequential interleaving, any mismatches between the sub-ADCs cause spurs in the spectrum, which are calibrated in this work as explained earlier in this section. However, despite calibration, residual interleaving spurs remain, due to the very high sensitivity of these interleaving spurs to mismatches that remain uncorrected after calibration. Further, some of the second-order interleaving mismatches, like linearity mismatches between the sub-ADCs, are not calibrated due to their complexity. For large-signal inputs, the SFDR of a sequentially IL ADC with interleaving mismatch calibrations is typically limited by HD2 or HD3 spurs caused by sampling distortion.

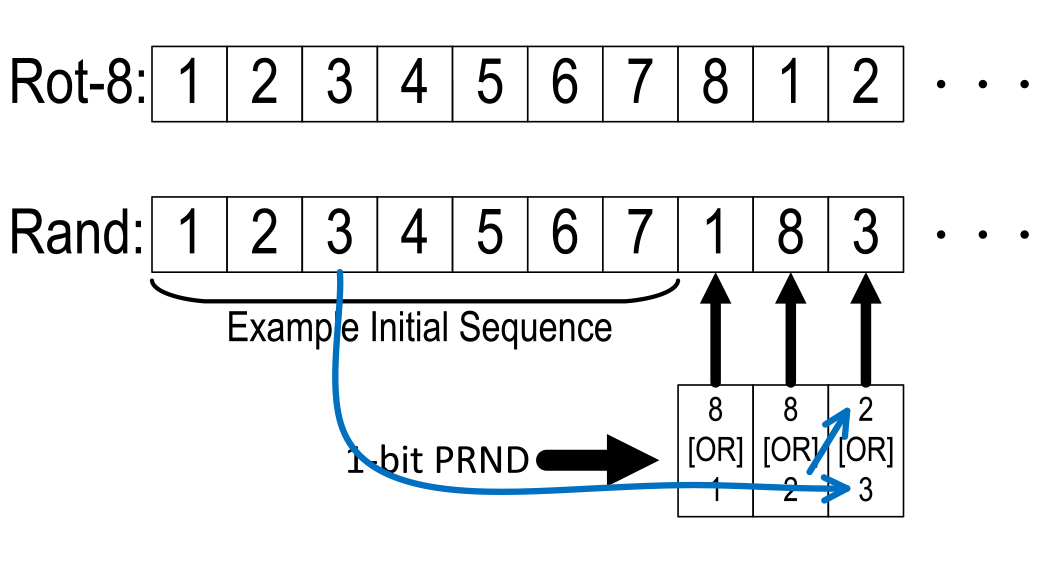
Fig. 14. Interleaving sub-ADC selection patterns for sequential and random modes of operation.
However, as the input signal becomes smaller, the HD2 and HD3 typically improve as the square and cube of the signal reduction, respectively, so the small-signal SFDR can quickly become limited by residual interleaving spurs, which is undesirable for many broadband applications. Further in some applications HD2 and HD3 spurs may be frequency-planned to fall outside the desired frequency band of interest, but residual interleaving spurs may fall in band, which is again undesirable.
To overcome this residual interleaving spur limitation, this work includes the ability to randomize sub-ADC selection patterns at the full 10-GS/s sample rate. Randomization helps convert any residual interleaving spurs into noise, thereby producing a cleaner spectrum, with the trade-off being an increase in the noise floor. To allow randomization, each of the eight sub-ADCs is designed to run at 1.43 GS/s [=(10 GS/s)/7], so after seven clock periods a sub-ADC is available for selection again. This redundancy results in two sub-ADCs being available for selection at any time, and the selection between these two sub-ADCs is controlled by a 1-b random generator (Pseudo Random, or PRND). The bottom half of Fig. 14 describes the random selection sequence pictorially. Assuming an initial starting sequence of 1 through 7, for the 8th sample both sub-ADCs 8 and 1 are available. If, for example, the PRND selects sub-ADC 1 for the 8th sample, then sub-ADC 8 remains in the stack at the same position and sub-ADC 2 gets added to the stack. For the 9th sample, if sub-ADC 8 is selected, then sub-ADC 2 takes its place and sub-ADC 3 takes the place of sub-ADC 2 in the stack. After sub-ADC conversions, the samples are reassembled in the correct sequence, thereby reversing the random scrambling sequence. The timing within the sub-ADC for an example sub-ADC selection sequence is shown in Fig. 15, wherein the MDAC1 tracks (T) the input signal for one period, then takes a sample and goes into hold (H) for a minimum of six periods, which includes the time required for generation of flash data and MDAC amplification to create the residue [28]. The IL calibration algorithms for gain, offset, and timing mismatches are unchanged when randomizing. For estimating timing skew, it was mentioned earlier that a correlation is performed between a given sub-ADC output and the sample immediately after it, which would be produced randomly by each of the other seven sub-ADCs when randomizing. This correlation, on average, still accurately estimates the timing skew of the given sub-ADC even when randomizing.

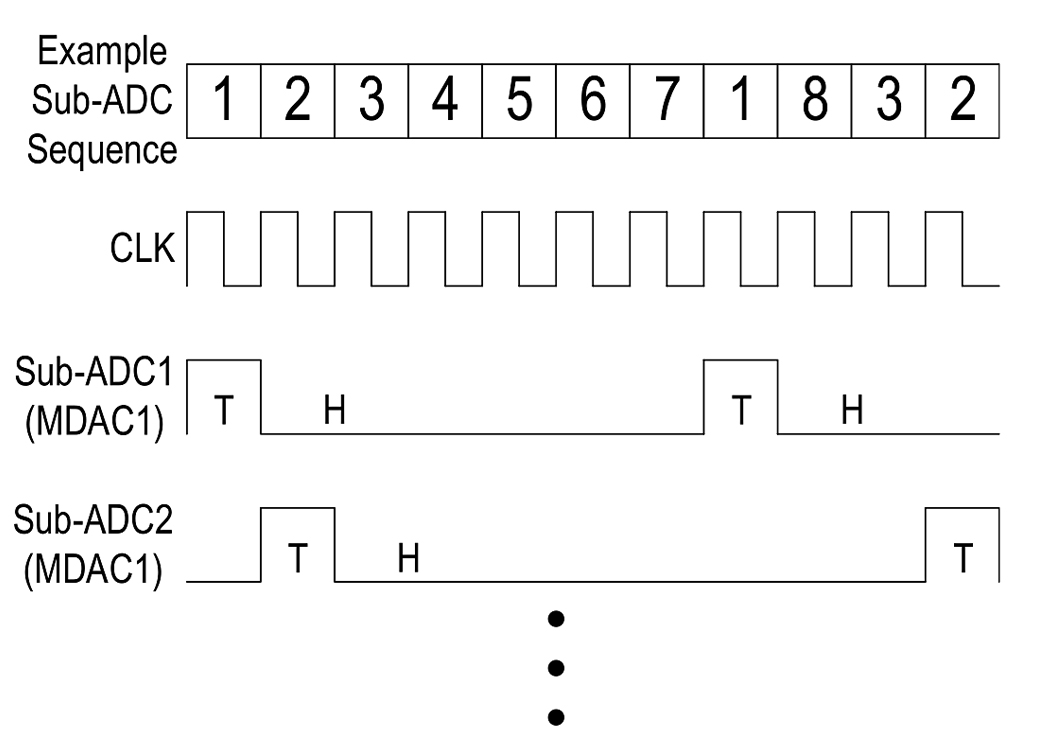
Fig. 15. Timing diagram of individual sub-ADCs relative to the overall sub-ADC selection pattern.

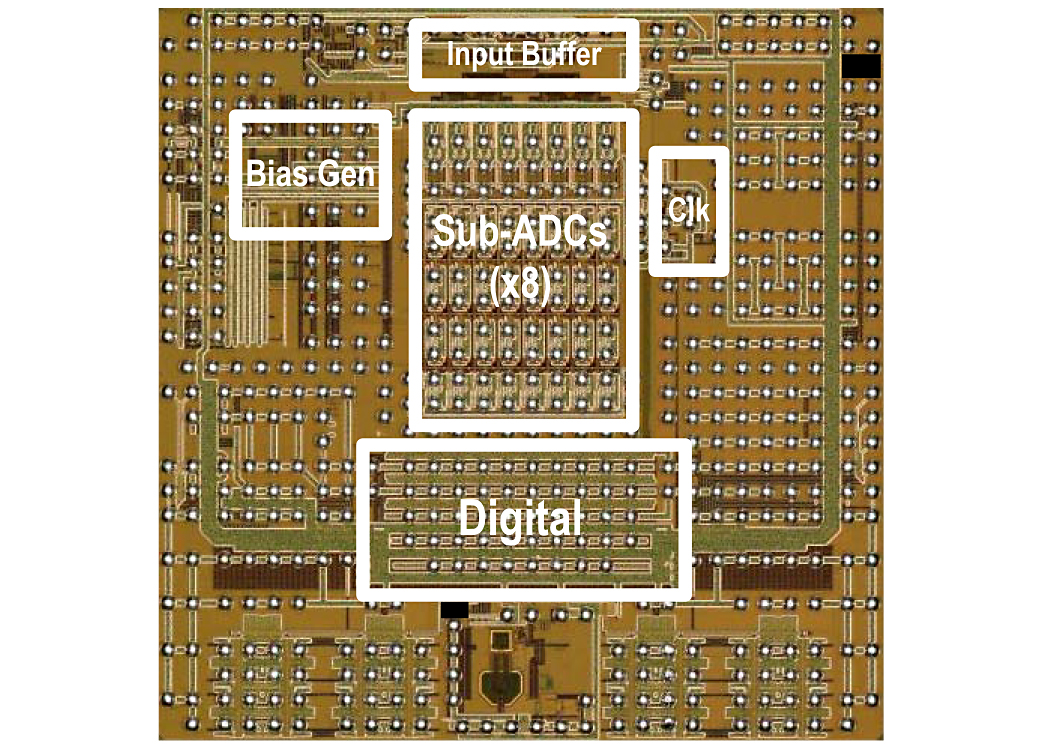
Fig. 16. Die Photograph—Highlighted area: 7.4 sq. mm. and die dimensions 4.5 mm × 4.5 mm.
Measurement Results
The 12-b 10-GS/s ADC is fabricated in a 28-nm CMOS technology. The die photograph of the ADC is shown in Fig. 16, with the key sections of the chip highlighted. The input buffer is at the top, followed by the eight IL sub-ADCs below it, followed by the digital. The clock receiver and all the clock phase generation circuitry is on the right, and the bias generation is on the left.
Fig. 17 shows the measured digital stage1 residue transfer function (DSRTF) of one of the sub-ADCs, with the back-end (stages 2 to 5) codes on the y-axis and the flash1 output codes on the x-axis. With the flash comparator background offset calibration enabled, a substantial portion of the correction range remains unused. Next, Fig. 18 shows the DSRTF with all the correction range used when the ADC is sampling a 4-GHz signal before the flash sample clock delay is trimmed to match the MDAC. Finally, Fig. 19 shows the DSRTF with the flash sample clock delay trimmed, where, even with a 4-GHz input signal substantial portion of the correction range remains unused.

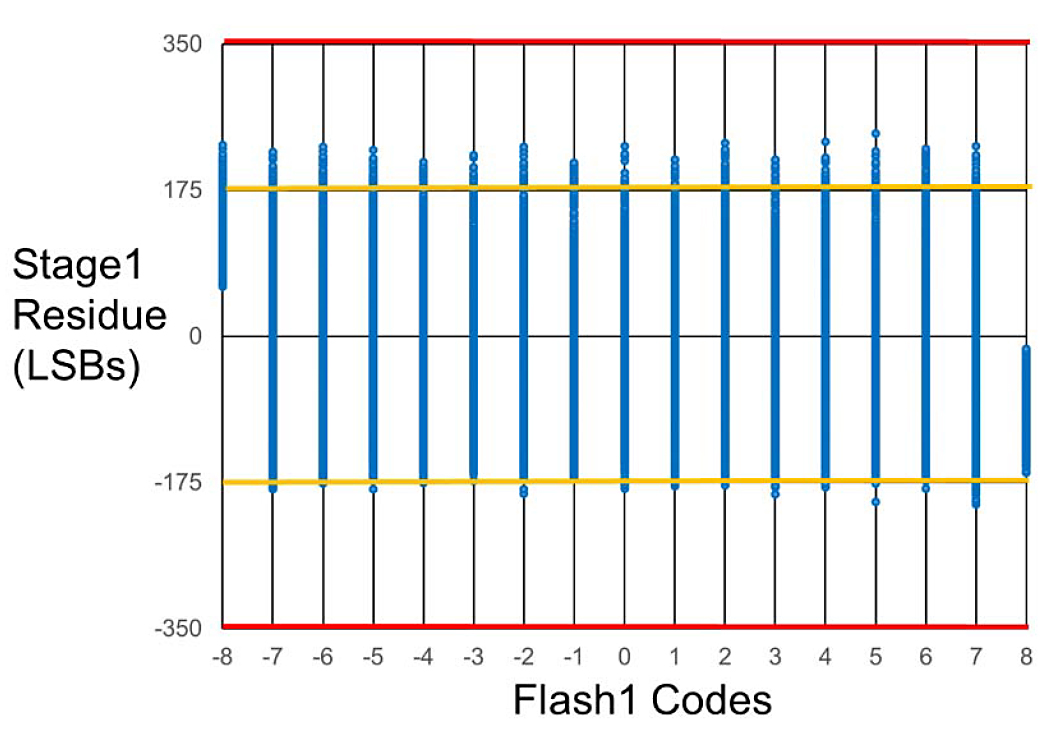
Fig. 17. Measured DSRTF with low-frequency (127 MHz) input with flash1 background calibration.

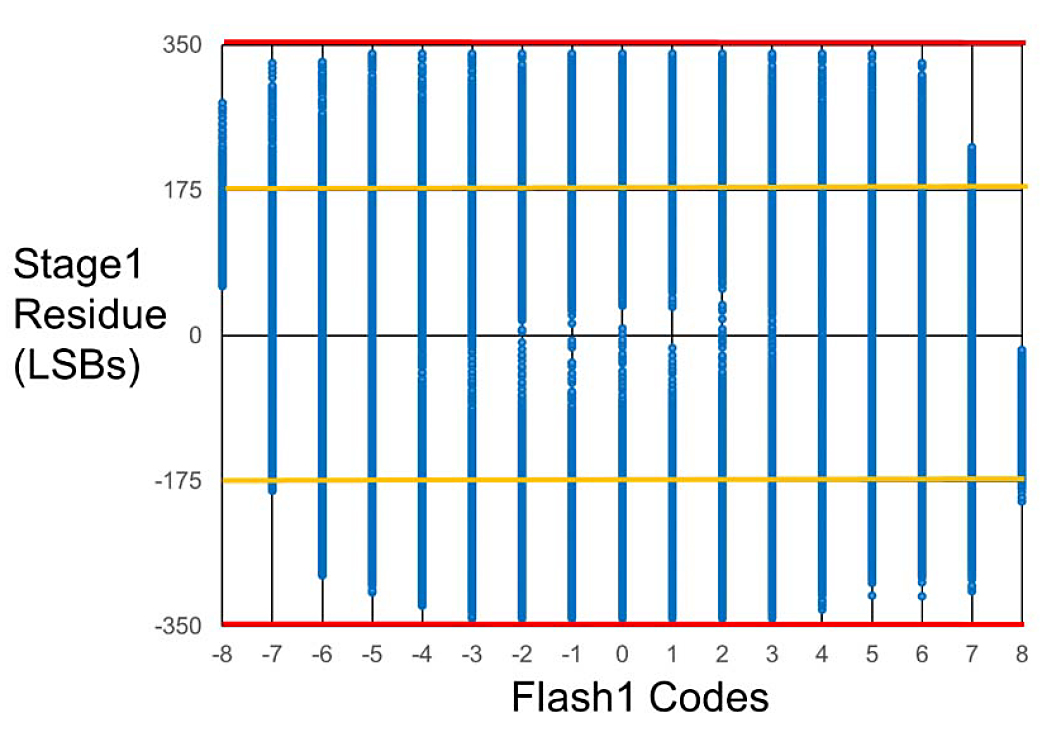
Fig. 18. Measured DSRTF with high-frequency (4 GHz) input without flash1 sample clock delay trim.

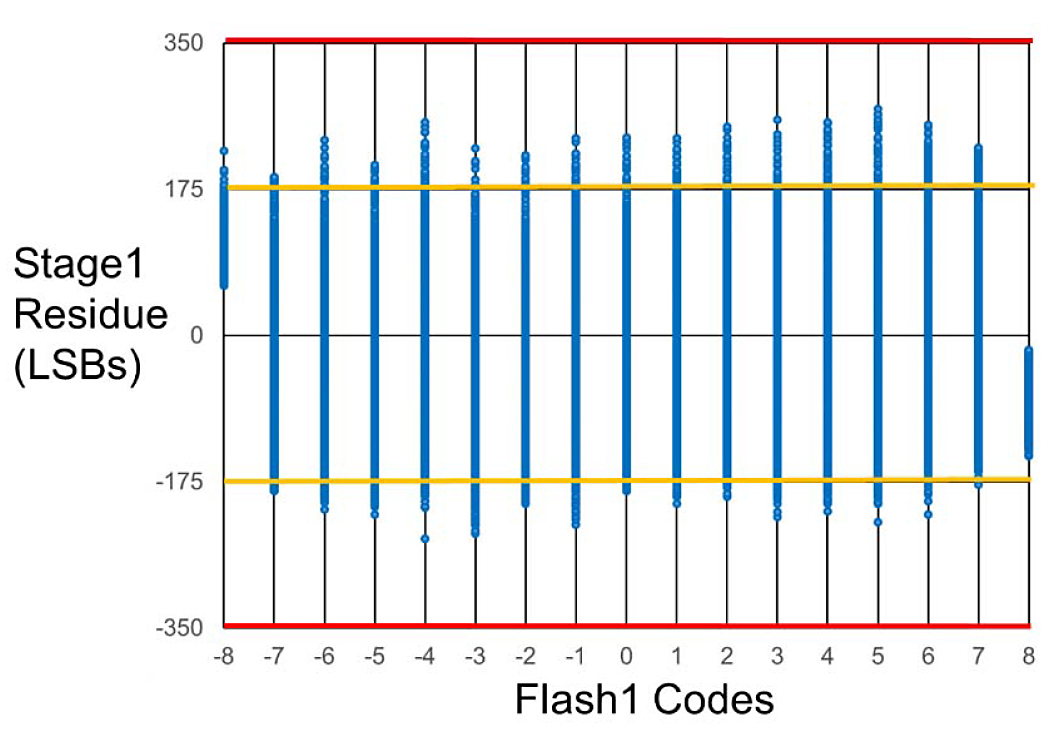
Fig. 19. Measured DSRTF with a high-frequency (4 GHz) input with flash1 sample clock delay trim.
Fig. 20 shows the measured Integral Non-Linearity (INL) transfer function of one of the eight sub-ADCs for three cases. With IGE calibration and dithering disabled, the INL has sharp discontinuities exceeding ±2 LSBs. Enabling IGE calibration reduces that to about ±1.5 LSBs. Finally with dithering also enabled the INL is less than ±0.7 LSBs. Dithering and IGE calibration significantly improve sub-ADC linearity and ensure a smooth INL transfer function. Having linear sub-ADCs with no transfer function discontinuities is a prerequisite to achieving good interleaving performance.

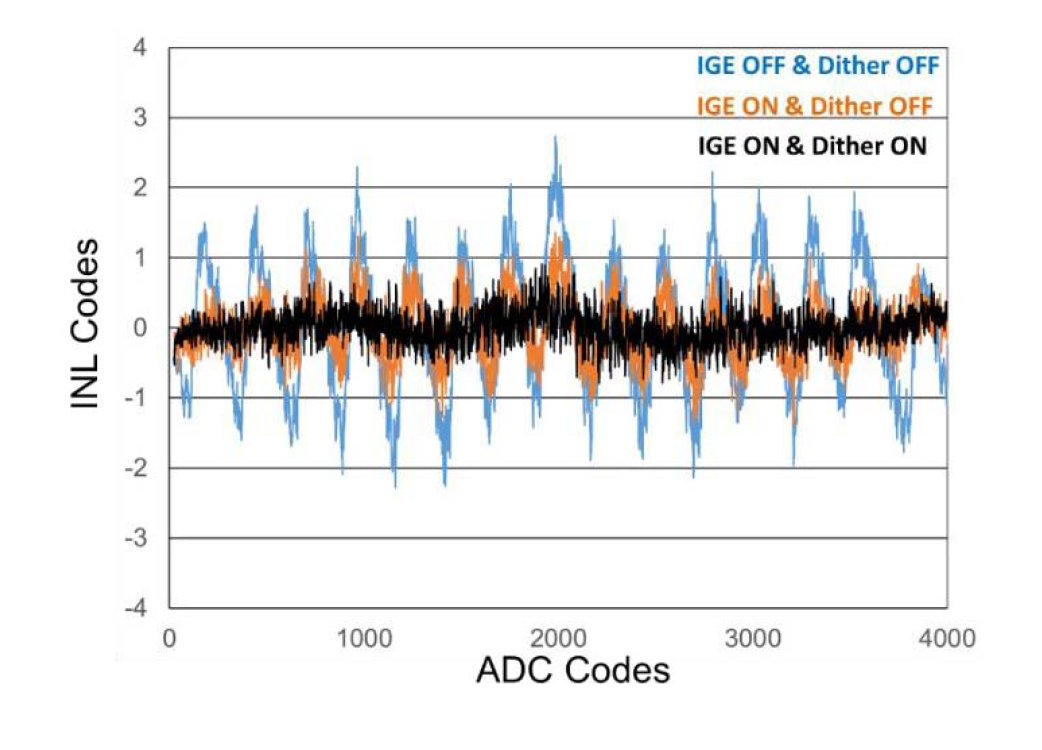
Fig. 20. Measured Sub-ADC INL transfer functions with and without dithering and IGE calibration.
Fig. 21 shows a measured fast Fourier transform (FFT) of the IL ADC sampling a 4-GHz input signal at 10 GS/s, with the sub-ADC calibrations and dithering enabled, but without interleaving calibrations. The spectrum shows large interleaving mismatch spurs that limit SFDR. When the interleaving calibrations are enabled, as shown in Fig. 22, the interleaving mismatch spurs are reduced below 80 dB, and the SFDR is limited by HD2 to 66 dB and HD3 is at 69 dB, while the achieved SNR is 56 dB and SNDR is 55 dB. An input frequency sweep of SNR, SNDR, and SFDR is shown in Fig. 23. Table I summarizes the performance specifications of this 12-b 10-GS/s ADC, and lists both the Schreier FOM (FOMS_HF) and the Walden FOM (FOMW_HF) [8].
| Resolution | 12b |
| FSAMPLE | 10GS/s |
| SNR | 56dB |
| SNDR | 55dB |
| SFDR | 66dB |
| 66dB | 4GHz |
| Power | 2.9W |
| FOMS_HF | 147dB |
| FOMW_HF | 631fJ/Conv-Step |
| BW | 7.4GHz |
| DR | 60dB |
| NSDsmall-signal | -157dBFS/Hz |
| Technology | 28nm |

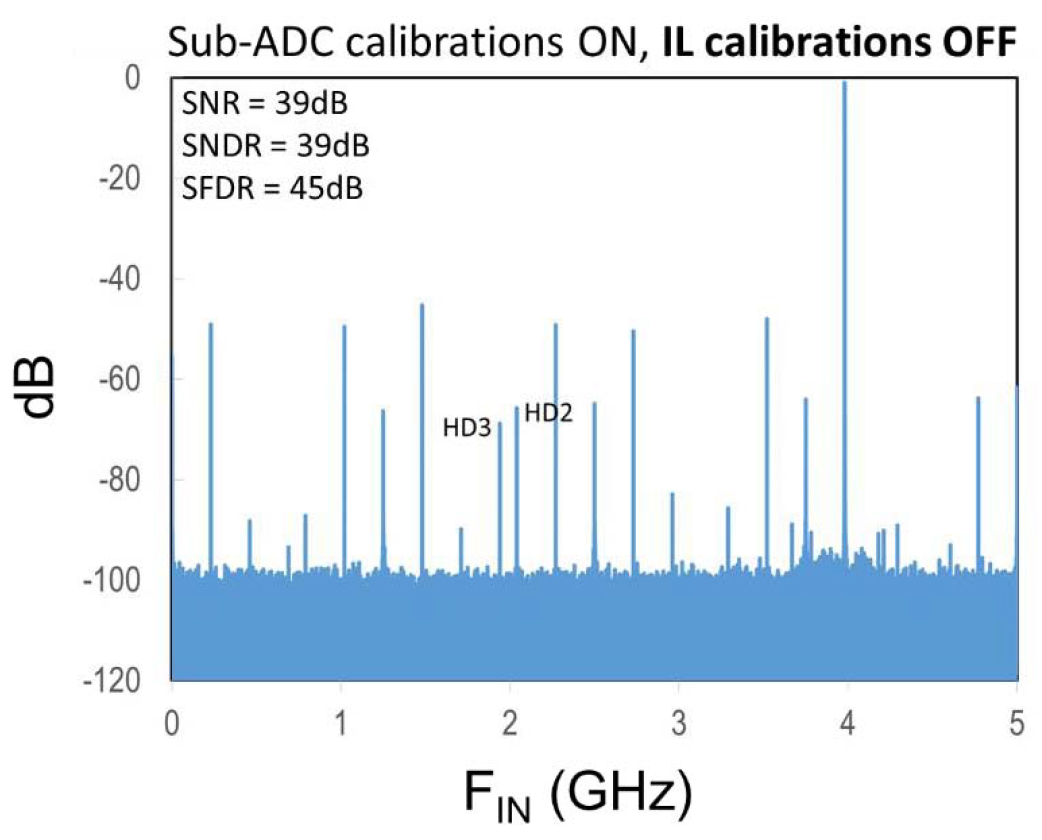
Fig. 21. Measured ADC FFT at 10 GS/s with a 4-GHz input with IL calibrations disabled.

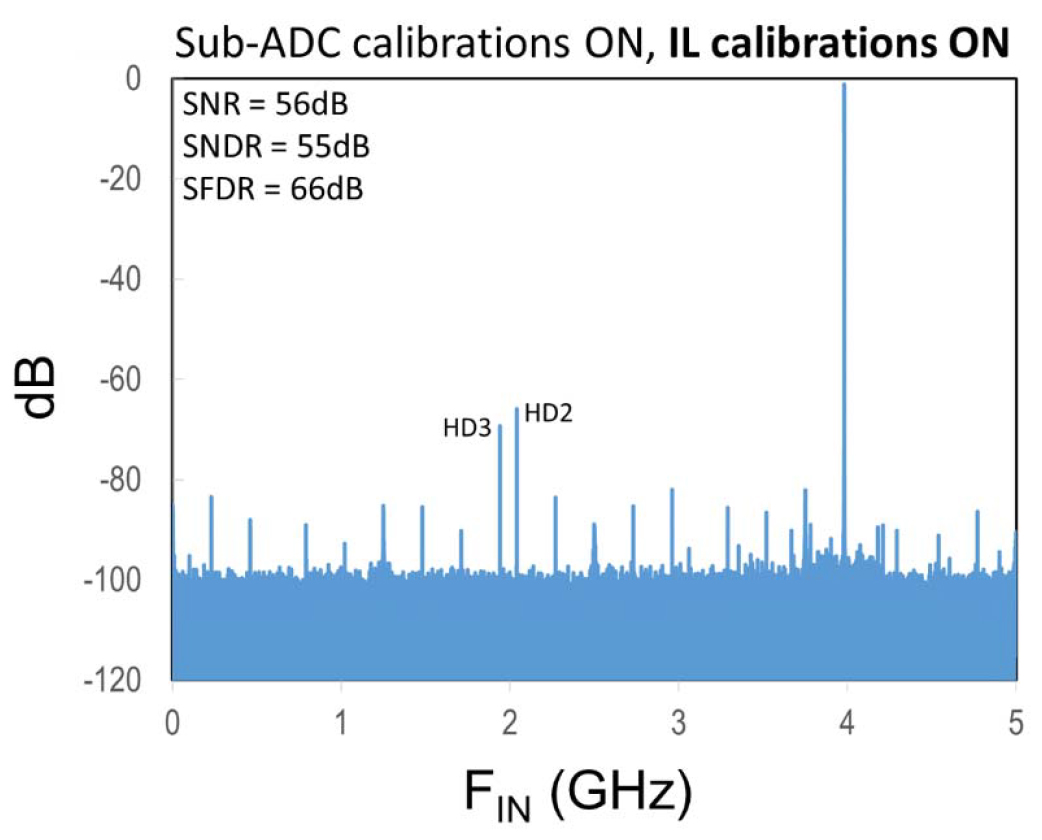
Fig. 22. Measured ADC FFT at 10 GS/s with a 4 GHz input with IL calibrations enabled.

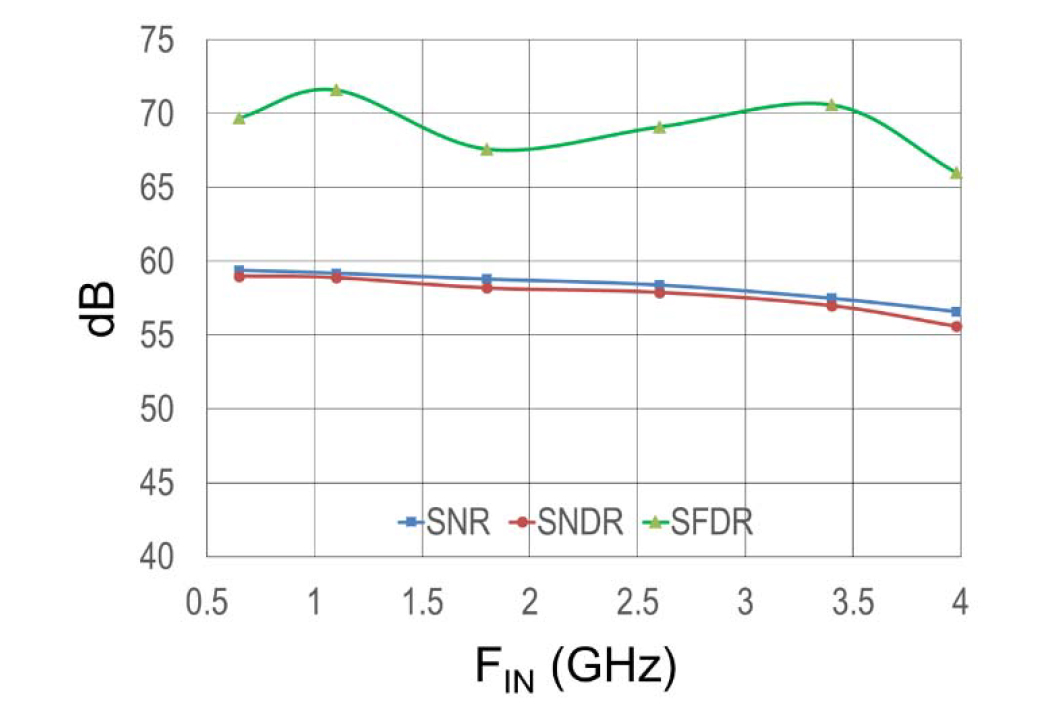
Fig. 23. Measured ADC input frequency sweep at 10 GS/s.
Fig. 24 shows the measured –3 dB BW of this ADC, which is about 7.4 GHz. The primary circuits determining the BW performance are the front-end push–pull input buffer and the fan-out driving the sampling networks within each sub-ADC.

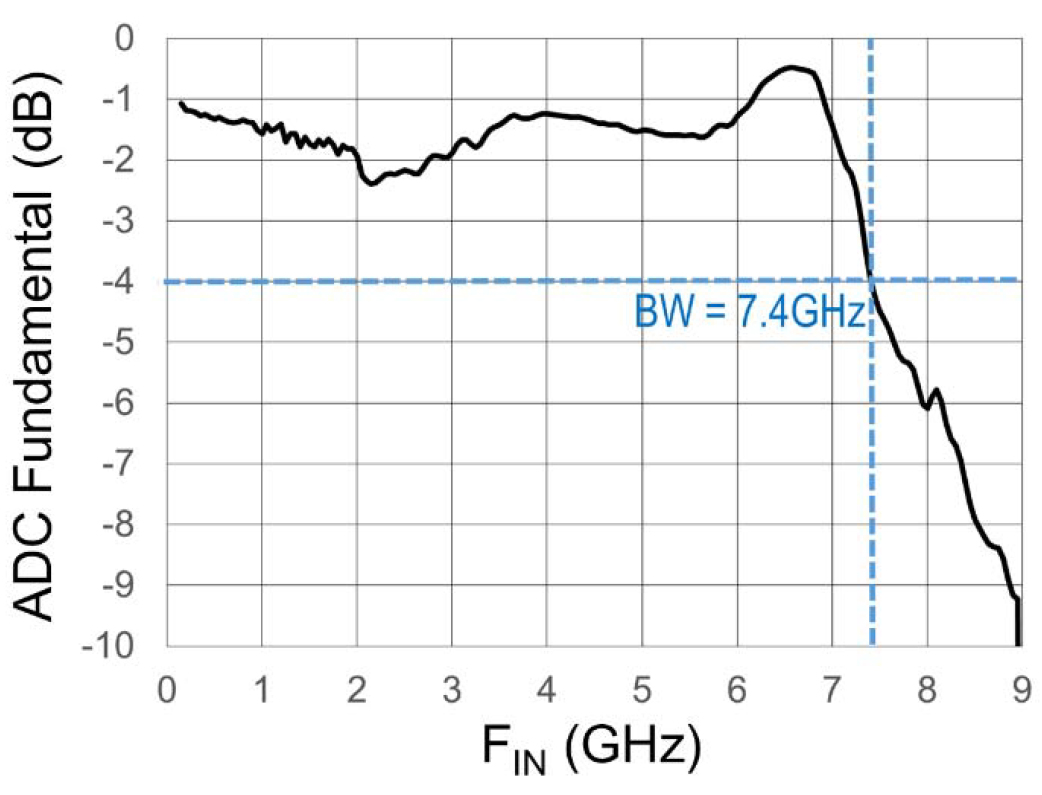
Fig. 24. Measured ADC input BW.
As discussed in Section III-C, this ADC includes the ability to randomize sub-ADC selection to improve spectral performance by reducing the magnitude of the residual interleaving spurs. To explain the effects of randomization, a sequence of measured FFT spectrums is shown next. Fig. 25 shows an FFT of the ADC sequentially sampling a close to full-scale 1-GHz signal at 10 GS/s, where the SFDR is limited by the HD3 component to 71 dBc and the interleaving mismatch spurs are suppressed to the 80-dB level by the calibrations. However, when the input signal amplitude drops by 6 dB, as shown in Fig. 26, the HD2 and HD3 improve by the square and the cube of the signal reduction, and SFDR is now limited to 70 dBc by the interleaving mismatch spurs, which is undesirable since many applications expect SFDR to improve at smaller signal amplitudes. Now, when randomization of the sub-ADCs is enabled, as shown in Fig. 27, these residual interleaving mismatch spurs are smeared into the noise floor and, for the case shown, the SFDR improves by 10 dB to 80 dBc while the trade-off is that the NSD degrades 1.5 dB.

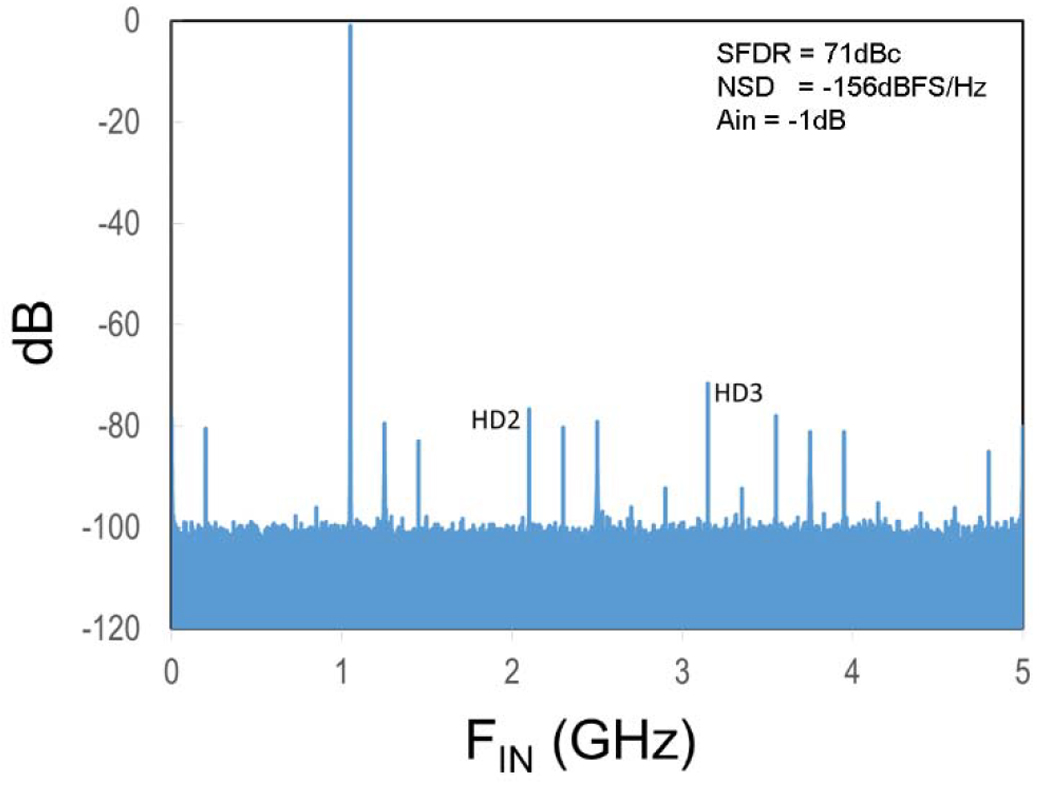
Fig. 25. Sequential IL 10-GS/s FFT with a full-scale signal.

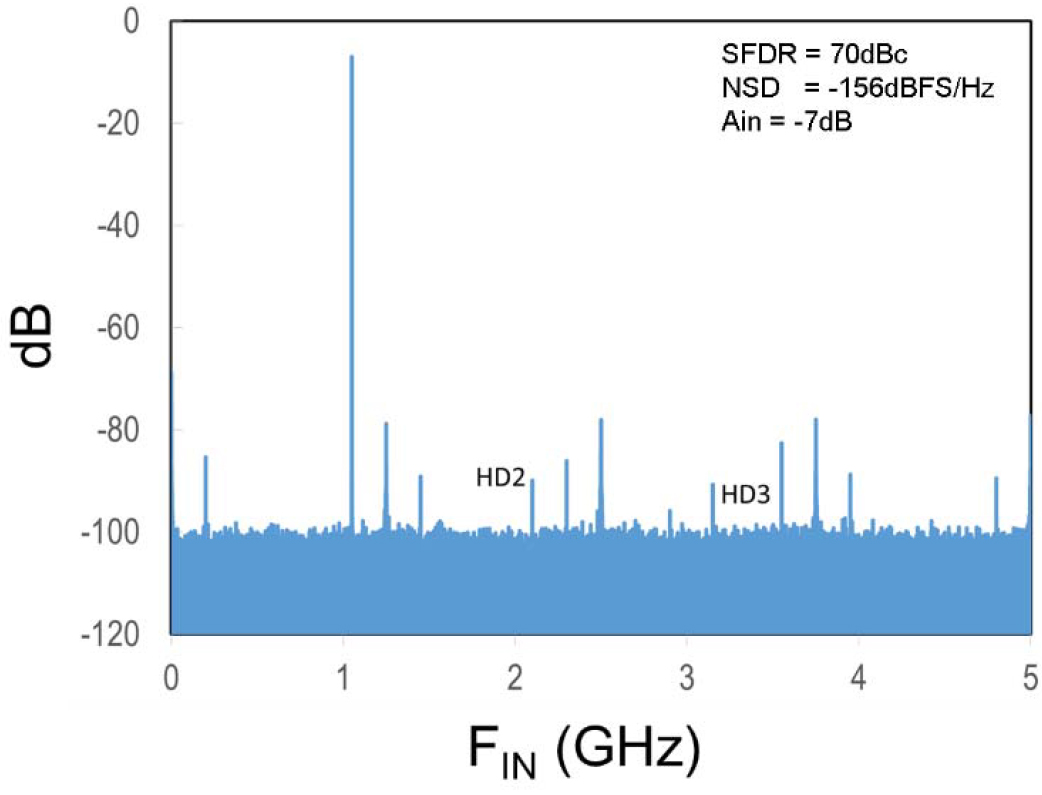
Fig. 26. Sequential IL 10-GS/s FFT showing dominant residual IL tones with a small-scale signal.

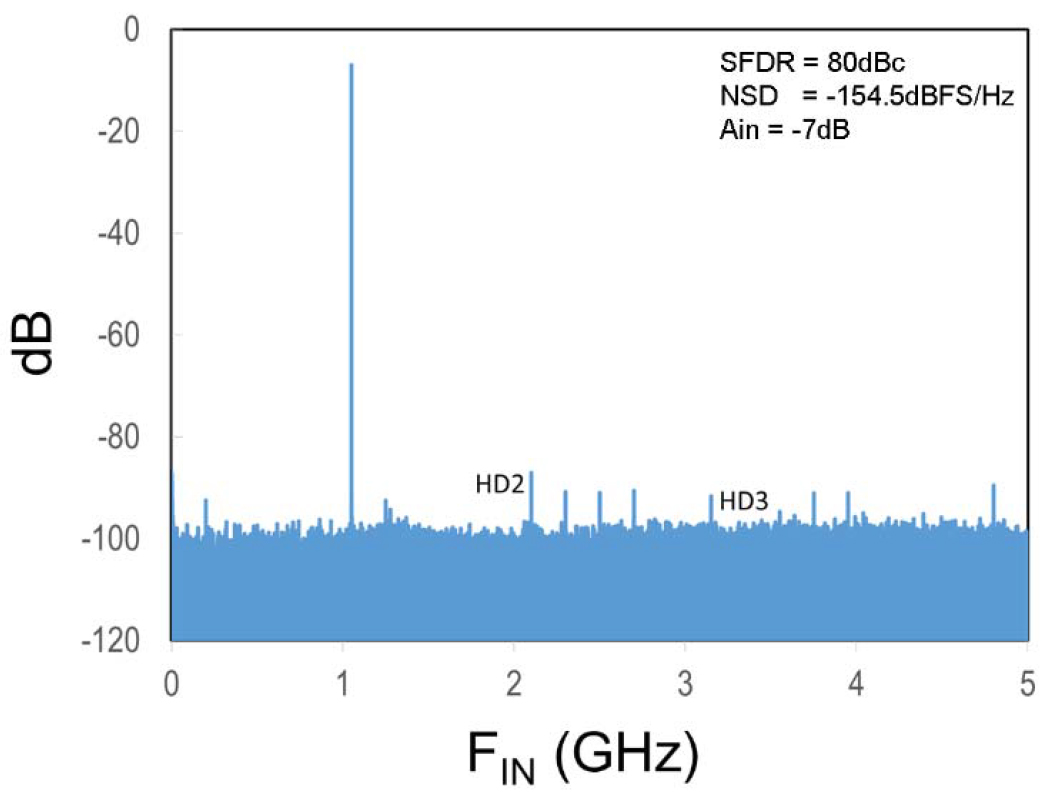
Fig. 27. Random IL 10-GS/s FFT showing reduced residual IL tones with a small-scale signal.
Finally, the power consumption of the ADC at 10 GS/s is 2.9 W, which includes about 400 mW for the input buffer, 1800 mW for the eight sub-ADCs, 650 mW for clocking and digital, and 50 mW for reference and bias generation.

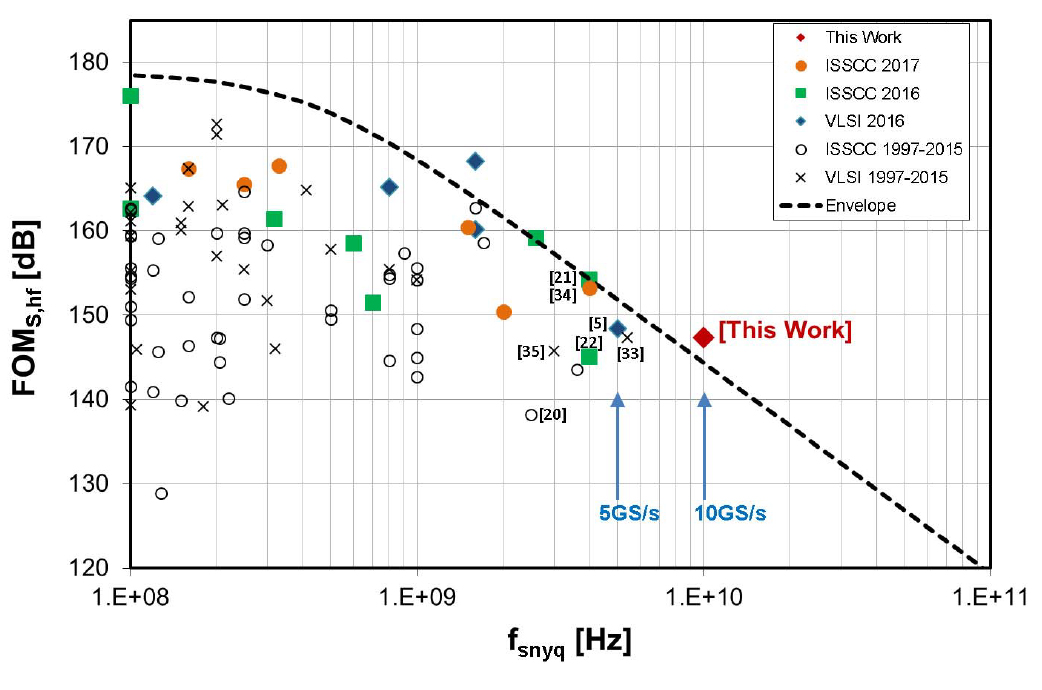
Fig. 28. Schreier FOM of ADCs with SNDR ≥ 50 dB (filtered from [8] after including ISSCC 2017 data).
Comparison With State-Of-The-Art ADCs
The Schreier FOM, shown in (1), is used to compare the performance of this 12-b 10-GS/s ADC with other ADCs in the literature. Fig. 28 shows an FOM comparison plot based on data from Murmann [8], where the ADCs have been filtered by the condition that SNDR = 50 dB, and Table II compares this work with recently published ADCs with fS = 2.5 GS/s from Fig. 28. This work achieves almost twice the sample rate of [5] and [33], both in 28-nm CMOS, while achieving similar FOM. While [21] and [34] achieve better FOM in 16-nm CMOS, they are 2.5× slower than this work. Almost all of these ADCs use an IL pipeline architecture. The process technology used for these IL pipeline ADCs in Table II range from 130-nm BiCMOS to 16-nm CMOS.
| Specification | This Work | [5] Ali | [33] Wu | [21] Wu | [22] Staayer | [34] Vaz | [35] Chen | [20] Setterberg |
| FSAMPLE | 10GS/s | 5GS/s | 5.4GS/s | 4GS/s | 4GS/s | 4GS/s | 3GS/s | 2.5GS/s |
| Input fin | 4GHz | 2GHz | 2.7GHz | 1.9GHz | 1.8GHz | 1.9GHz | 1.5GHz | 1GHz |
| SNDR @ fin | 55dB | 58dB | 50dB | 56dB | 56dB | 57dB | 51dB | 61dB |
| SFDR @ fin | 66dB | 70dB | 65dB | 68dB | 64dB | 67dB | — | 78dB |
| Power (W) | 2.9 | 2.3 | 0.5 | 0.3 | 2.2 | 0.5 | 0.5 | 24 |
| FOMS @ fin | 147dB | 148dB | 147dB | 154dB | 145dB | 153dB | 146dB | 138dB |
| BW | 7.4GHz | 5GHz | — | — | 4GHz | — | — | — |
| Process | 28nm | 28nm | 28nm | 16nm | 65nm | 16nm | 40nm | 130nm BiCMOS |
| Architecture | IL Pipe | IL Pipe | IL Pipe | IL Pipe | IL Pipe | IL Pipe/SAR | IL Pipe | IL Pipe |
Summary and Conclusion
A 12-b 10-GS/s ADC that interleaves eight pipeline sub-ADCs in 28-nm CMOS technology is described in this paper. The SHA-less pipeline sub-ADCs, including the MDAC amplifiers, operate off the core power supply for low-power dissipation, which is made possible with techniques such as residue scaling, flash background calibration, dithering, and IGE calibration. The challenges of achieving BW and linearity in an IL ADC are addressed with a push–pull complementary input buffer to drive the IL sub-ADCs, and a fast bootstrap switch enables 10-GS/s sampling operation. Interleaving mismatches are addressed with background calibration techniques. Random selection of sub-ADCs is shown to reduce residual interleaving spurs.
关于作者
关联至此文章
行业解决方案
技术解决方案
























